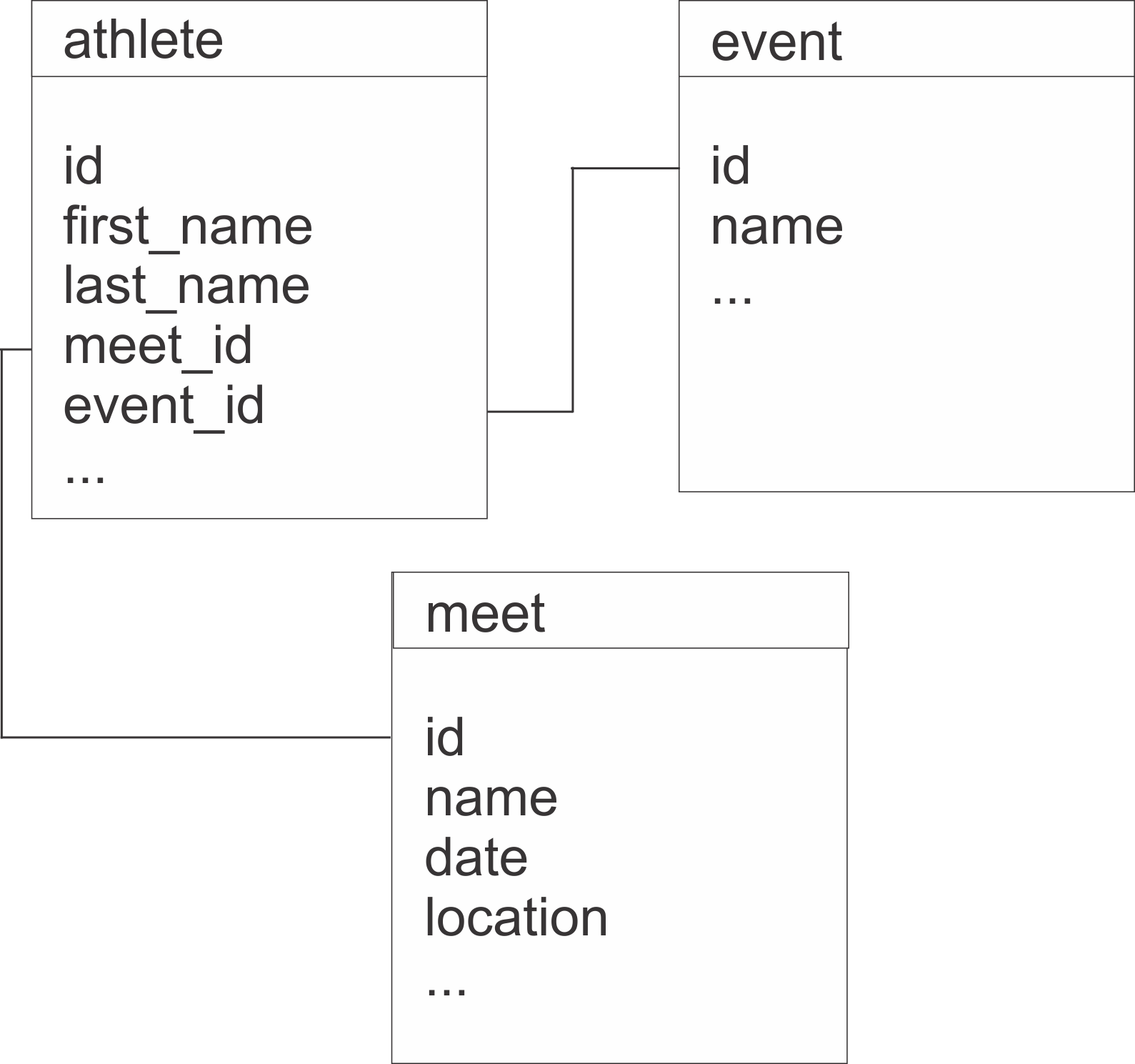
There are a lot of options available when one starts exploring the exciting field of the Internet of Things, or IoT. Not only are there many choices of micro-controllers, there are also a variety of languages in which to program these devices. Many times the micro-controllers are sold as being dependent on C or C++ as a language. That’s great, but I don’t know either of those. There is some great and amazing working being led by Andrew Chalkley around using the JavaScript language for micro-controllers over at thingsSDK. If JavaScript is your language, I’d highly recommend checking out their work. There are also lots of resources for using Java for IoT, Nathan Tippy, for example, is an excellent resource.
All those are great languages. What if you are a beginning developer just interested in playing around in IoT? Or what if you are a Pythonista and don’t want to pick up another programming language? Well, for many micro-controllers there is a Python option which is, arguably easier to learn in many ways than Java, JavaScript, C or C++. That option being MicroPython. You can see that project’s website here.
Overview of MicroPython
MicroPython is a tiny, open source Python programming language interpreter that runs on embedded boards. It was originally developed in 2013 and released in 2014 by Dr. Damian P. George of Cambridge University. It implements Python 3 and is designed specifically to run on devices with limited resources.
As with many things in the IoT world, the use of a particular language is greatly influenced by the tools, libraries, and packages one has available. MicroPython comes with an interactive read-evaluate-print-loop (REPL) for quick prototyping. It also fully supports loading MicroPython scripts onto a device to run as well. It supports an extensive Python based library and for lower level operations can be extended with C/C++ functions as needed.
Many of the tasks that beginning IoT folks start off with, such as blinking lights, reading switches, driving servos, etc. are all easy to do in MicroPython. Further, it is often incredibly easy to read as well, as it is all Python based. For example, if one has MicroPython installed on a NodeMCU ESP8266 board, a popular and inexpensive board to start working in IoT, with a basic LED light connected to GPIO Pin 5 it is pretty simple to get the light to turn on (high state) and off (low state).
import machine led = machine.Pin(5, machine.Pin.OUT) # Turn on LED led.high() # Turn off LED led.low()
The machine module is included with MicroPython and handles many of the hardware connections from software. It allows access to things like GPIO pins, CPU frequency, I2C busses, etc. If it is low-level on the hardware, the machine module is the way to go!
Platform Support
There are many devices that support MicroPython. The NodeMCU is one of them. But several other options are available such as the LoPy or similar PyCom devices, the PyBoard, and many others.
Differences from Python 3
As one can imagine, cramming everything from Python 3 into a micro-controller isn’t possible. But, core data types and modules which make sense for embedded systems are included. Another limitation is that since Python is a high-level programming language it isn’t as fast or lean as C or C++. Many operations aren’t impacted by this. However, if your application requires tight timing or performance is of utmost importance, using MicroPython can be an issue. However, as stated earlier, one can extend MicroPython to use C/C++ in these circumstances.
Since MicroPython is open source, check it out on GitHub, one can further extend or adapt it specific use case scenarios. For example, if you need something specific to run at boot time you can include it in the package that is flashed to the device. Pretty handy and convenient.
Conclusion
Hopefully I have at least sparked your interest enough in using MicroPython for IoT to take a further look at it. The development site actually has a live, interactive device where you can try out some code and see it run on a real world device. Give it a try and leave a comment below to share with others what you’ve done and built!
Follow me on Twitter @kenwalger to get the latest updates on my postings.