
Databases, such as MongoDB, are very good at querying lots of data and updating that data frequently. In most cases, however, we are only performing queries on the latest state of the data. What about situations in which we need to query previous states of the data? What if we need to have some functionality of version control of our documents? This is where we can use the Document Versioning Pattern.
This pattern is all about keeping the version history of documents available and usable. We could construct a system that uses a dedicated version control system in conjunction with MongoDB. One system for the few documents that change and MongoDB for the others. This would be potentially cumbersome. By using the Document Versioning Pattern, however, we are able to avoid having to use multiple systems for managing the current documents and their history by keeping them in one database.
The Document Versioning Pattern
This pattern addresses the problem of wanting to keep around older revisions of some documents in MongoDB instead of bringing in a second management system. To accomplish this, we add a field to each document allowing us to keep track of the document version. The database will then have two collections: one that has the latest (and most queried data) and another that has all of the revisions of the data.
The Document Versioning Pattern makes a few assumptions about the data in the database and the data access patterns that the application makes.
- Each document doesn’t have too many revisions.
- There aren’t too many documents to version.
- Most of the queries performed are done on the most current version of the document.
If you find that these assumptions don’t fit your use case, this pattern may not be a great fit. You may have to alter how you implement your version of the Document Versioning Pattern or your use case may simply require a different solution.
Sample Use Case
The Document Versioning Pattern is very useful in highly regulated industries that require a specific point in time version of a set of data. Financial and healthcare industries are good examples. Insurance and legal industries are some others. There are many use cases that track histories of some portion of the data.
Think of how an insurance company might make use of this pattern. Each customer has a “standard” policy and a second portion that is specific to that customer, a policy rider if you will. This second portion would contain a list of policy add-ons and a list of specific items that are being insured. As the customer changes what specific items are insured, this information needs to be updated while the historical information needs to be available as well. This is fairly common in homeowner or renters insurance policies. For example, if someone has specific items they want to be insured beyond the typical coverage provided, they are listed separately, as a rider. Another use case for the insurance company may be to keep all the versions of the “standard policy” they have mailed to their customers over time.
If we take a look at the requirements for the Document Versioning Pattern, this seems like a great use case. The insurance company likely has a few million customers, the revisions to the “add-on” list likely don’t occur too frequently, and the majority of searches on a policy will be about the most current version.
Inside our database, each customer might have a current_policy document — containing customer specific information — in a current_policies collection and policy_revision documents in a policy_revisions collection. Additionally, there would be a standard_policy collection that would be the same for most customers. When a customer purchases a new item and wants it added to their policy, a new policy_revision document is created using the current_policy document. A version field in the document is then incremented to identify it as the latest revision and the customer’s changes added.

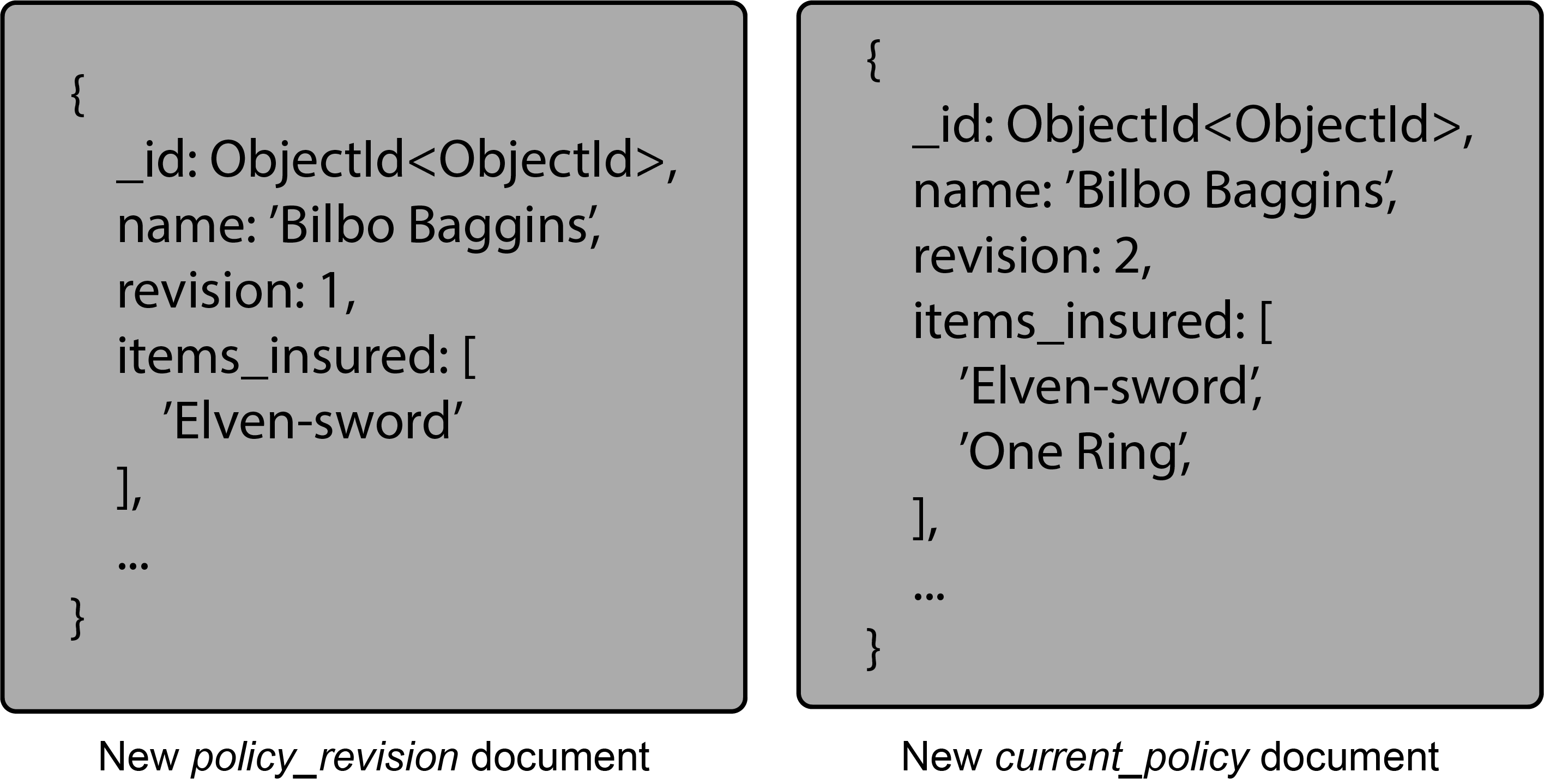
The newest revision will be stored in the current_policies collection and the old version will be written to the policy_revisions collection. By keeping the latest versions in the current_policy collection queries can remain simple. The policy_revisions collection might only keep a few versions back as well, depending on data needs and requirements.

In this example then, Middle-earth Insurance would have a standard_policy for its customers. All residents of The Shire would share this particular policy document. Bilbo has specific things he wants insuring on top of his normal coverage. His Elven Sword and, eventually, the One Ring are added to his policy. These would reside in the current_policies collection and as changes are made the policy_revisions collection would keep a historical record of changes.
The Document Versioning Pattern is relatively easy to accomplish. It can be implemented on existing systems without too many changes to the application or to existing documents. Further, queries accessing the latest version of the document remain performant.
One drawback to this pattern is the need to access a different collection for historical information. Another is the fact that writes will be higher overall to the database. This is why one of the requirements to use this pattern is that it occurs on data that isn’t changed too frequently.
Conclusion
When you need to keep track of changes to documents, the Document Versioning Pattern is a great option. It is relatively easy to implement and can be applied to an existing set of documents. Another benefit is that queries to the latest version of data still perform well. It does not, however, replace a dedicated version control system.
The next post in this series will look at the final design pattern, Schema Versioning.
If you have questions, please leave comments below.
Previous Parts of Building with Patterns:
- The Polymorphic pattern
- The Attribute pattern
- The Bucket pattern
- The Outlier pattern
- The Computed pattern
- The Subset pattern
- The Extended Reference pattern
- The Approximation pattern
- The Tree pattern
- The Pre-allocation pattern