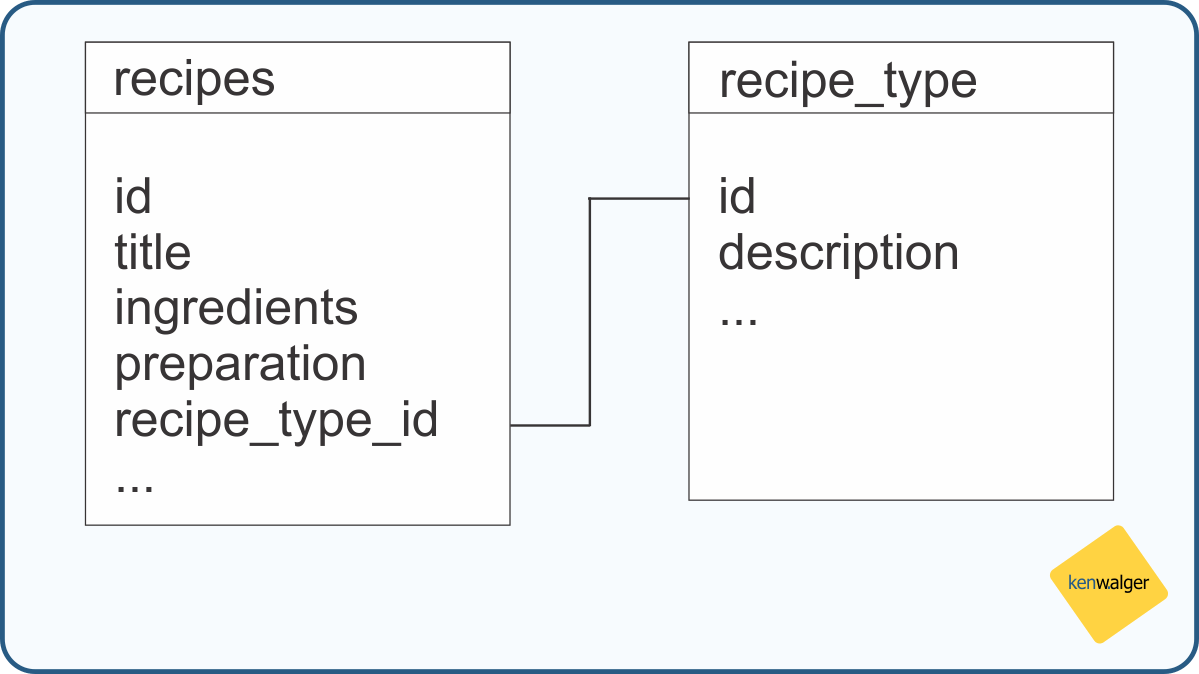
I’ve previously touched on some of the benefits and a few examples of how to do schema design in MongoDB. One often raised question when it comes to modeling data in MongoDB is how best to handle data schema in a non-relational database. I’d like to explore in more depth some of the considerations required for effective schema design for MongoDB implementations.
One of the key things to remember when modeling your data in MongoDB is how the application is going to use the data. Your data access patterns should be of foremost thought when designing your data model. Unlike data normalization concerns in relational databases, embedding data in a document often provides better performance.
When, however, does one decide to embed documents inside another document? What are some of the considerations for doing so when thinking about schema design?
Types of Relationships
In the relational database world modeling different relationships comes down to examining how to model “One-to-N” relationships and the normalization of data. In MongoDB, there are a variety of ways to model these relationships. When doing schema design in MongoDB there is more to consider than a blanket model for a “One-to-N” relationship model.
We need to consider the size of “N” for our modeling because in this instance, size matters. One-to-one relationships can easily be handled with embedding a document inside another document. But what happens if “N” grows? Let’s have a look at the following cases, “One-to-few”, “One-to-Many”, and “One-to-Tons”.
One-to-Few
This is a pretty common occurrence, even in the relational database world. A single record that needs to be associated with a relatively small number of other data points. Something like keeping customer information and their associated phone numbers or addresses. We can embed an array of information inside the document for the customer.
{
"_id" : ObjectId("56cb1cfb72d245023179fda4"),
"name" : "Harvey Waldrip",
"phone" : [
{ "type" : "mobile", "number" : "503-555-5555" },
{ "type" : "home", "number" : "503-555-1111"}
]
}
This showcases the benefits, and drawbacks, of embedding. We can easily get the embedded information with a single query. The downside, however, is that the embedded can’t be accessed as autonomous data.
One-to-Many
“Many” here covers up to a few thousand or so in number. Say that we are modeling a product made up of smaller parts. For example, if we had an electronic parts kit each part in the kit could be referenced as a separate part.
each part in the kit could be referenced as a separate part.
{
"_id" : ObjectId("AAAA"),
"part_no" : "150ohm-0.5W"
"name" : "150ohm 1/2 Watt Resistor"
"qty" : 1
"cost" : { NumberDecimal("0.13"), currency: "USD" }
}
Each piece in the kit would have its own document. Notice the format of the “cost” value, I discussed that in a post on Modeling Monetary Data in MongoDB. Each final product, or kit in our example, will contain an array of references to the necessary parts.
{
"_id" : ObjectId("57d7a121fa937f710a7d486e"),
"manufacturer" : "Elegoo",
"catalog_number" : 123789,
"parts" : [
ObjectID("AAAA"),
ObjectID("AAAB"),
ObjectID("G9D6"),
...
]
}
Now we can utilize an application level join or depending on the use case the $lookup aggregation pipeline operator to get information about specific parts in a kit. For best performance, we need to make sure we have proper indexes in place on our collections as well.
This style of reference allows for quick and easy search and updating of the parts in the kit. It has basically become an “N-to-N” schema design without needing a separate join table. Pretty slick.
One-to-Tons
As I mentioned, “One-to-Many” is great for up to several thousand references. But what about cases when that isn’t enough? Further, what if the referencing poses schema design concerns around the document limitation of 16MB? This is where parent referencing becomes very useful.
Let’s imagine an event log situation. We would have a document for the host machine and store that host machine in the log message documents.
Host
{ "_id" : "Bunyan",
"name" : "logger.lumberjack.com",
"ip_address" : "127.55.55.55"
}
Message
{ "_id" : "MongoDB",
"time" : ISODate("2017-08-29T17:25:00.000Z"),
"message" : "Timber!!!",
"host" : ObjectId("Bunyan")
}
Again, for optimum searching, we would want to make sure indexes are properly in place.
Schema Design – Key Considerations
Now that we have seen some of the schema design options, how do we determine which is the best one to utilize? There are a few things to think about before choosing and have somewhat become the standard questions to ask when doing schema design in MongoDB.
Golden Rules for MongoDB Schema Design
- Unless there is a compelling reason to do so, favor embedding.
- Needing to access an object on its own is a compelling reason to not embed the object in another document.
- Unbounded array growth is a bad design.
- Don’t be afraid of joins on the application side. A properly indexed collection and query can have highly performant results.
- When denormalizing your data, consider the read to write ratio of the application.
- Finally, how you model your data depends on your application’s data access patterns. Match your schema design to how your application reads and writes the data.
Wrap Up
There are some great references available for designing your schemas in MongoDB. Some of my favorites are MongoDB Applied Design Patterns and MongoDB in Action
and MongoDB in Action . While I have not seen or read it, The Little Mongo DB Schema Design Book
. While I have not seen or read it, The Little Mongo DB Schema Design Book looks like a promising resource as well.
looks like a promising resource as well.
Juan Roy has a nice slide deck available on this topic as well. Definitely worth having a look.
There are several MongoDB specific terms in this post. I created a MongoDB Dictionary skill for the Amazon Echo line of products. Check it out and you can say “Alexa, ask MongoDB what is a document?” and get a helpful response.
Follow me on Twitter @kenwalger to get the latest updates on my postings.