
One of the great things about MongoDB is the document data model. It provides for a lot of flexibility not only in schema design but in the development cycle as well. Not knowing what fields will be required down the road is easily handled with MongoDB documents. However, there are times when the structure is known and being able to fill or grow the structure makes the design much simpler. This is where we can use the Preallocation Pattern.
Memory allocation is often done in blocks to avoid performance issues. In the earlier days of MongoDB (prior to MongoDB version 3.2), when it used the MMAPv1 storage engine, a common optimization was to allocate in advance the memory needed for the future size of a constantly growing document. Growing documents in MMAPv1 needed to be relocated at a fairly expensive cost by the server. With its lock-free and rewrite on update algorithms, WiredTiger does not require this same treatment.
With the deprecation of MMAPv1 in MongoDB 4.0, the Preallocation Pattern appeared to lose some of its luster and necessity. However, there are still use cases for the Preallocation Pattern with WiredTiger. As with the other patterns we’ve discussed in the Building with Patterns series, there are a few application considerations to think about.
The Preallocation Pattern
This pattern simply dictates to create an initial empty structure to be filled later. It may sound trivial, however, you will need to balance the desired outcome in simplification versus the additional resources that the solution may consume. Bigger documents will make for a larger working set resulting in more RAM to contain this working set.
If the code of the application is much easier to write and maintain if it uses a structure that is not completed filled, it may easily outweigh the cost of the RAM. Let’s say there is a need to represent a theater room as a 2-dimensional array where each seat has a “row” and “number”, for example, the seat “C7”. Some rows may have fewer seats, however finding the seat “B3” is faster and cleaner in a 2-dimensional array, than having a complicated formula to find a seat in a one-dimensional array that has only cells for the existing seats. Being able to identify accessible seating is also easier as a separate array can be created for those seats.
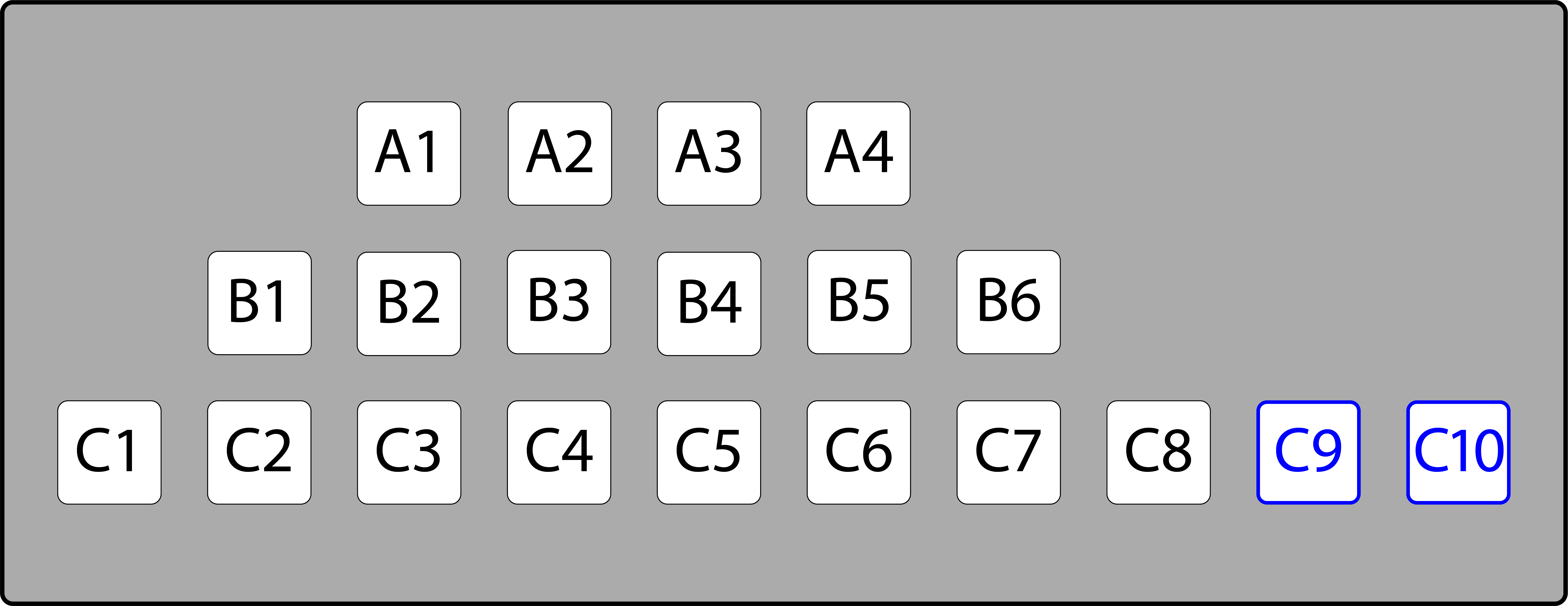
Two dimensional representation of venue, valid seats available in green. Accessible seating notated with a blue outline.

One dimensional representation of venue, accessible seats shown in blue.
Sample Use Case
As seen earlier, representing a 2 dimension structure, like a venue, is a good use case. Another example could be a reservation system where a resource is blocked or reserved, on a per day basis. Using one cell per available day would likely make computations and checking faster than keeping a list of ranges.

The month of April 2019 with an array of U.S. work days.
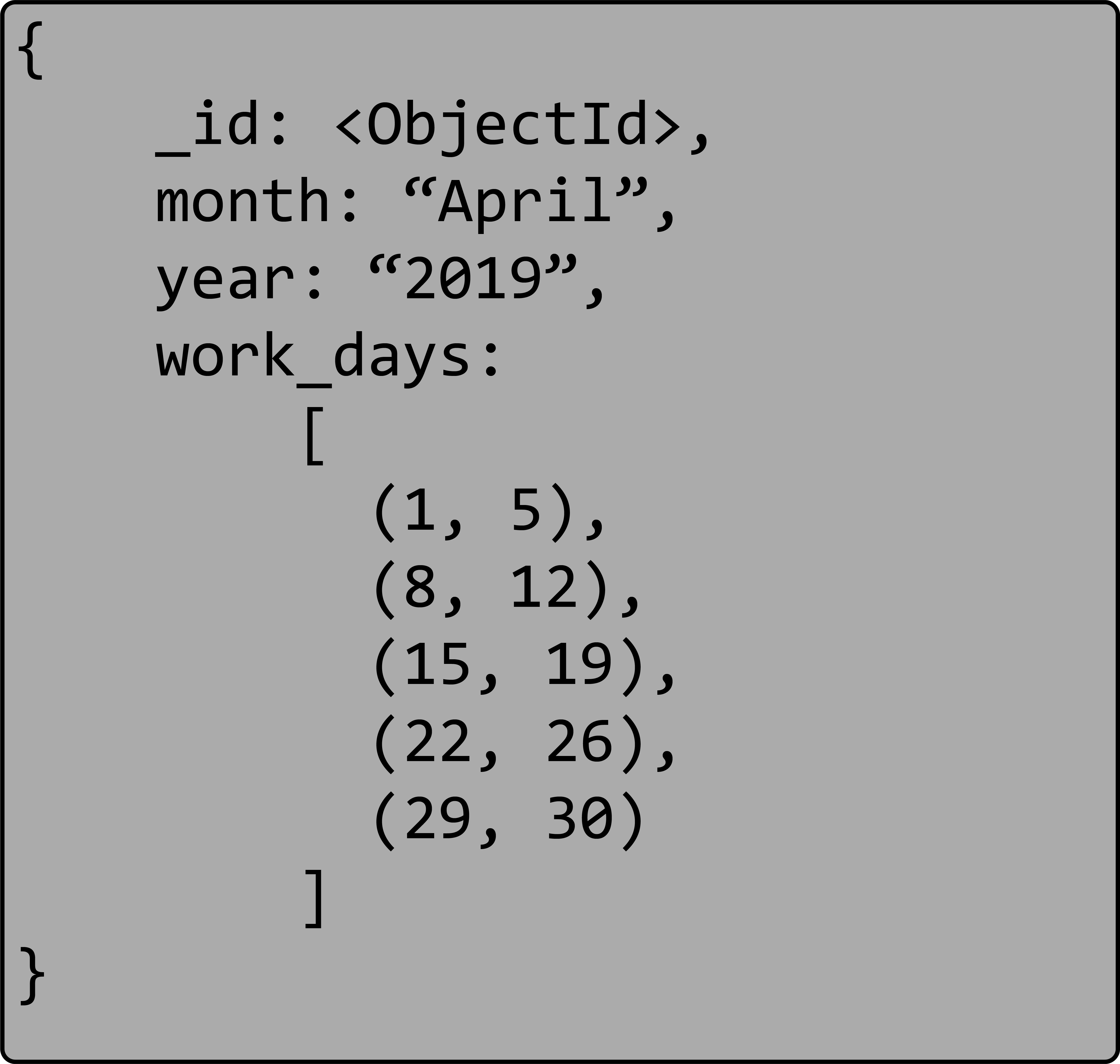
The month of April 2019 with an array of U.S. work days as a list of ranges.
Conclusion
This pattern may be one of the most used when using the MMAPv1 storage engine with MongoDB. However due to the depreciation of this storage engine, it has lost its generic use case, but it is still useful in some situations. And like other patterns, you have a trade-off between “simplicity” and “performance”.
The next post in this series will look at the Document Versioning Pattern.
If you have questions, please leave comments below.
Previous Parts of Building with Patterns:
- The Polymorphic pattern
- The Attribute pattern
- The Bucket pattern
- The Outlier pattern
- The Computed pattern
- The Subset pattern
- The Extended Reference pattern
- The Approximation pattern
- The Tree pattern