There are many different options available when developing to look at and examine your MongoDB collections. MongoDB’s Compass is a great example of a tool that allows for the viewing and interaction with a database, collection, or document. However, when developing it is often useful to have the ability to see your data inside your development environment. Let’s take a look at a useful MongoDB Plugin for PyCharm for viewing collections.
MongoDB Plugin
While I will be discussing the Mongo Plugin specifically as it relates to PyCharm, the plugin itself works with the vast majority of IDEs provided by JetBrains. After downloading and installing the plugin we need to set a few things up. I’ll walk through setting up connections for a local installation of a MongoDB server as well as a connection to their Database as a Service, Atlas. For testing the connection we will want to make sure both of these servers are up and running.
MongoDB Plugin Settings
Local Server
For the local server, the settings are relatively straight forward. Assuming that we are working with a server on the default port of 27107, let’s take a look at our settings.
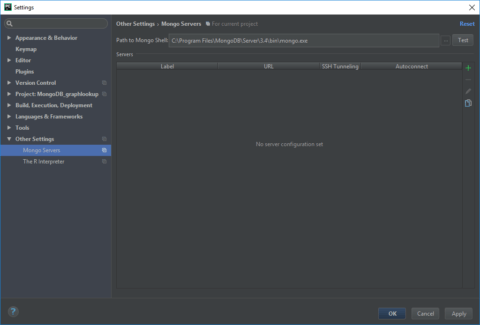
We see here that there is a place to input the path to our Path to Mongo Shell. Be sure to put the location to the mongo executable and not the one for mongod. You can hit the test button next to the path name to make sure the plugin is happy with the correct file.
We next need to add a server to use and connect with. By clicking on the + symbol we are presented with an option to configure our server connection.
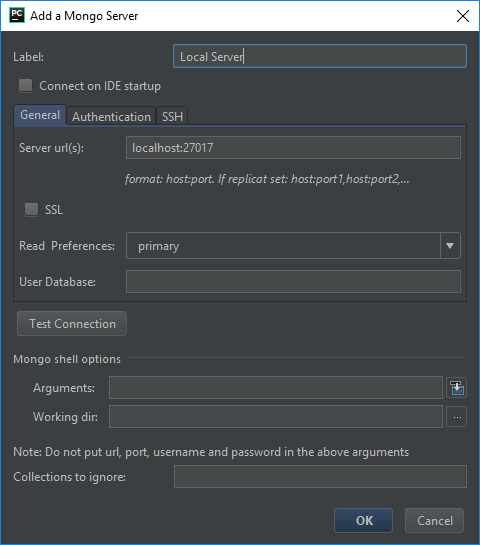
Here we see that we are able to label, or name, our connection and put in the server location in the format of host:port. For our example, we can use localhost:27017, as displayed above. For a single server without any authentication in place, these settings will connect to the database and you can see all of the databases on the server.
What if, however, you do have some authentication in place and want to establish a connection to a specific database? Let’s examine that with a connection to an Atlas configuration.
Atlas Server
We will need our Atlas connection URL that is available within our Atlas dashboard. Feel free to use your own server’s host name or IP address. For my server settings, I want to set a read preference for the Primary node and to connect to the travel collection in the database. I also selected that I’d like it to use SSL for the connection.
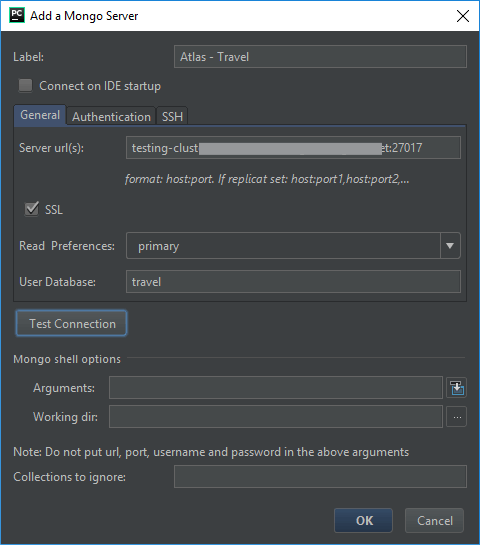
Since my Atlas server does require authentication, let’s take a look at that tab.
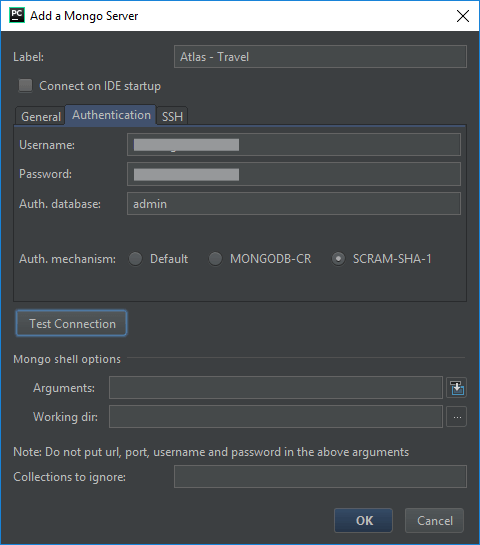
We put in an appropriately established username and password along with the name of the authentication database. In this case, I am using the admin database. For Atlas, we want to choose the SCRAM-SHA-1 authorization mechanism. And then we can test this connection. If everything is configured correctly, we should get the good news pop up.
Starting the Plugin
With our connections established, we can use the Mongo Explorer by navigating to View -> Tool Windows -> Mongo Explorer. It will show our configured connections and when opening the connection up we see our databases listed.
Upon selecting a given database we are given a list of the collections. We can then choose a given collection and see a list of the documents in the collection.
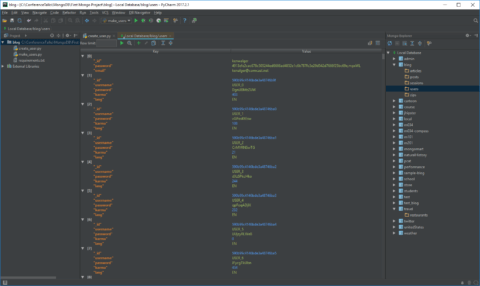
MongoDB Plugin ToolBar
If we have a look at the toolbar that appears above our collection:
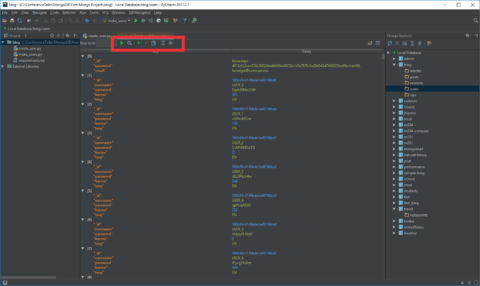
There are some great features in there.

We see that we have a find option, an option to toggle the aggregation mode, and the ability to add and edit documents directly from PyCharm. We are given options to run queries with Filter, Projection, and Sort parameters as well. A group of very useful tools included with this plugin.
Wrap Up
With successfully configured connections to MongoDB servers, we can now utilize the Mongo Plugin to see what our data looks like as we develop. I personally find this to be a huge benefit and time saver when developing. If you use a JetBrains IDE for your development, I would highly encourage you to have a look at this very useful plugin.
There are several MongoDB specific terms in this post. I created a MongoDB Dictionary skill for the Amazon Echo line of products. Check it out and you can say “Alexa, ask MongoDB what is a document?” and get a helpful response.
Follow me on Twitter @kenwalger to get the latest updates on my postings.