
One frequently asked question when it comes to MongoDB is “How do I structure my schema in MongoDB for my application?” The honest answer is, it depends. Does your application do more reads than writes? What data needs to be together when read from the database? What performance considerations are there? How large are the documents? How large will they get? How do you anticipate your data will grow and scale?
All of these questions, and more, factor into how one designs a database schema in MongoDB. It has been said that MongoDB is schemaless. In fact, schema design is very important in MongoDB. The hard fact is that most performance issues we’ve found trace back to poor schema design.
Over the course of this blog post series, we’ll take a look at twelve common Schema Design Patterns that work well in MongoDB. We hope this series will establish a common methodology and vocabulary you can use when designing schemas. Leveraging these patterns allows for the use of “building blocks” in schema planning, resulting in more methodology being used than art.
MongoDB uses a document data model. This model is inherently flexible, allowing for data models to support your application needs. The flexibility also can lead to schemas being more complex than they should. When thinking of schema design, we should be thinking of performance, scalability, and simplicity.
Let’s start our exploration into schema design with a look at what can be thought as the base for all patterns, the Polymorphic Pattern. This pattern is utilized when we have documents that have more similarities than differences. It’s also a good fit for when we want to keep documents in a single collection.
The Polymorphic Pattern
When all documents in a collection are of similar, but not identical, structure, we call this the Polymorphic Pattern. As mentioned, the Polymorphic Pattern is useful when we want to access (query) information from a single collection. Grouping documents together based on the queries we want to run (instead of separating the object across tables or collections) helps improve performance.
Imagine that our application tracks professional sports athletes across all different sports.
We still want to be able to access all of the athletes in our application, but the attributes of each athlete are very different. This is where the Polymorphic Pattern shines. In the example below, we store data for athletes from two different sports in the same collection. The data stored about each athlete does not need to be the same even though the documents are in the same collection.
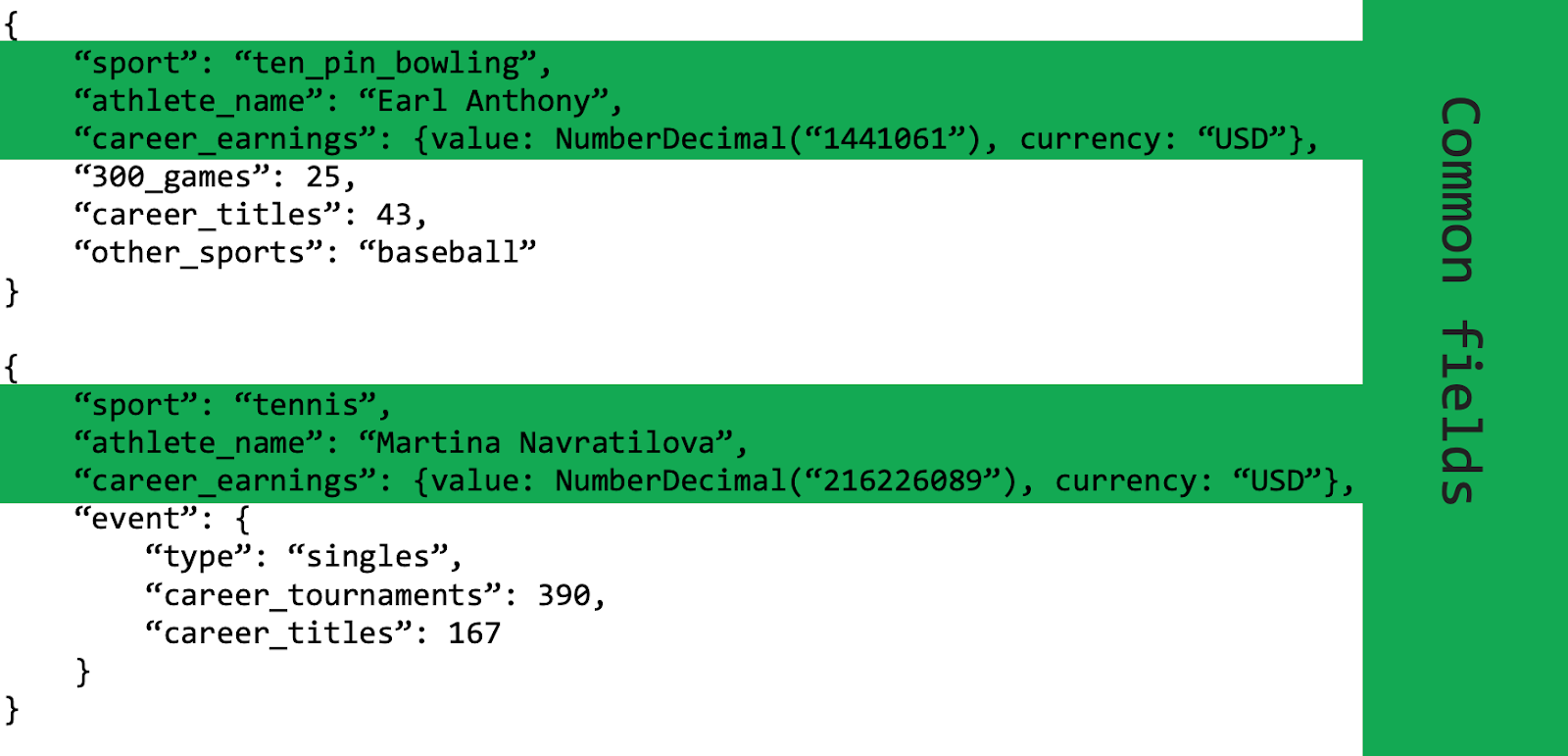
Professional athlete records have some similarities, but also some differences. With the Polymorphic Pattern, we are easily able to accommodate these differences. If we were not using the Polymorphic Pattern, we might have a collection for Bowling Athletes and a collection for Tennis Athletes. When we wanted to query on all athletes, we would need to do a time-consuming and potentially complex join. Instead, since we are using the Polymorphic Pattern, all of our data is stored in one Athletes collection and querying for all athletes can be accomplished with a simple query.
This design pattern can flow into embedded sub-documents as well. In the above example, Martina Navratilova didn’t just compete as a single player, so we might want to structure her record as follows:
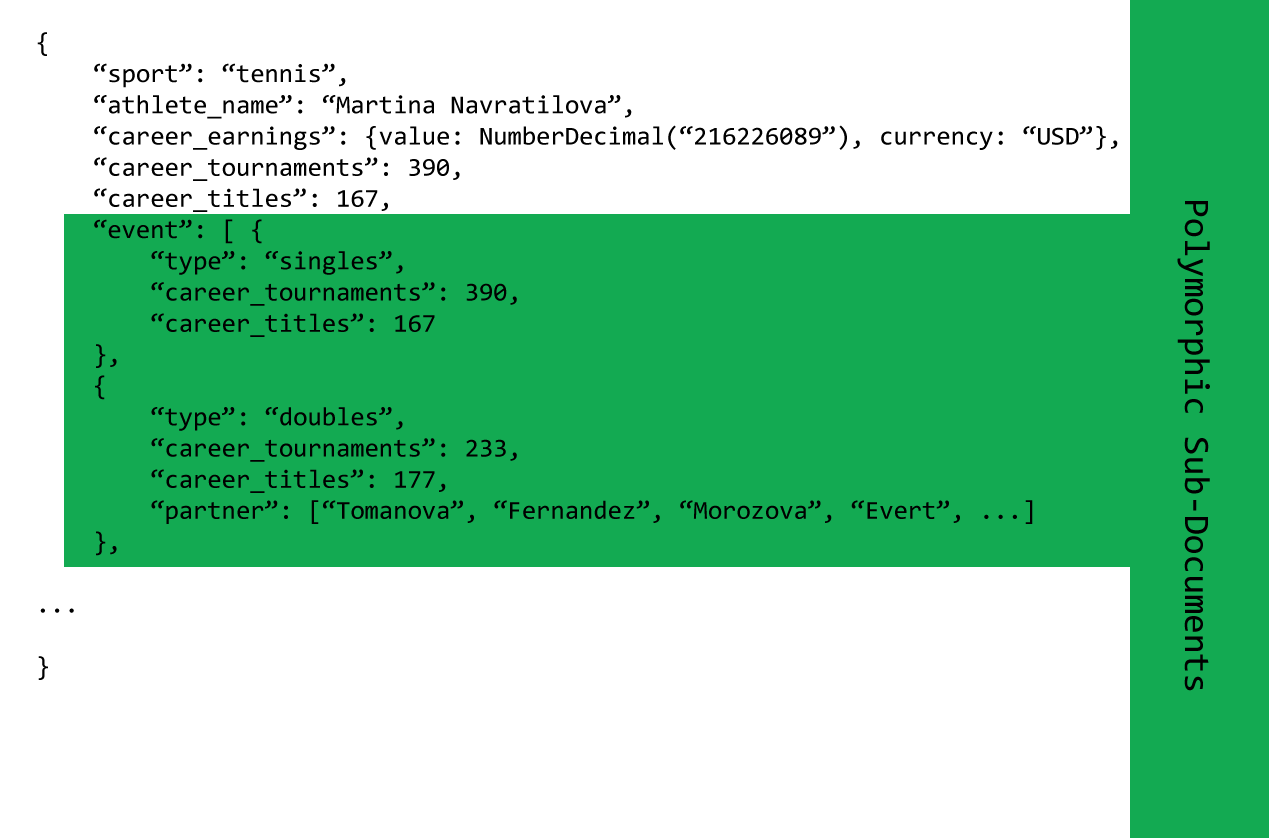
From an application development standpoint, when using the Polymorphic Pattern we’re going to look at specific fields in the document or sub-document to be able to track differences. We’d know, for example, that a tennis player athlete might be involved with different events, while a different sports player may not be. This will, typically, require different code paths in the application code based on the information in a given document. Or, perhaps, different classes or subclasses are written to handle the differences between tennis, bowling, soccer, and rugby players.
Sample Use Case
One example use case of the Polymorphic Pattern is Single View applications. Imagine working for a company that, over the course of time, acquires other companies with their technology and data patterns. For example, each company has many databases, each modeling “insurances with their customers” in a different way. Then you buy those companies and want to integrate all of those systems into one. Merging these different systems into a unified SQL schema is costly and time-consuming.
MetLife was able to leverage MongoDB and the Polymorphic Pattern to build their single view application in a few months. Their Single View application aggregates data from multiple sources into a central repository allowing customer service, insurance agents, billing, and other departments to get a 360° picture of a customer. This has allowed them to provide better customer service at a reduced cost to the company. Further, using MongoDB’s flexible data model and the Polymorphic Pattern, the development team was able to innovate quickly to bring their product online.
A Single View application is one use case of the Polymorphic Pattern. It also works well for things like product catalogs where a bicycle has different attributes than a fishing rod. Our athlete example could easily be expanded into a more full-fledged content management system and utilize the Polymorphic Pattern there.
Conclusion
The Polymorphic Pattern is used when documents have more similarities than they have differences. Typical use cases for this type of schema design would be:
- Single View applications
- Content management
- Mobile applications
- A product catalog
The Polymorphic Pattern provides an easy-to-implement design that allows for querying across a single collection and is a starting point for many of the design patterns we’ll be exploring in upcoming posts. The next pattern we’ll discuss is the Attribute Pattern.
If you have questions, please leave a comment below.
This post was originally published on the MongoDB Blog.

