

I get asked about and see a lot of posts and comments on the internet about MongoDB not being as quick on query reads as people think it should be. These questions and/or comments are often followed by a panning of MongoDB itself. Often based on the user’s experience in this one situation. My first question in these situations typically is “What indexes are set up on your collection that relate to your queries?” More often than not I get a deer in headlights look back at me. After some stammering, the answer typically is “I don’t know.”, “Is indexing important?”, “Whatever is standard.”, or the most popular, “What’s an index?”.
Indexing Overview
In this blog post, I’d like to touch briefly on what indexes are in MongoDB and how they greatly impact performance. What is an index? If we start with the definition provided by MongoDB:
Indexes are special data structures that store a small portion of the collection’s data set in an easy to traverse form.
we get an idea from the “easy to traverse” statement that they make something that is complicated, easier. In this case, indexes make traversing a collection easier (faster).
Let’s consider a data set that includes all of the postal codes in the United States. (zips.json can be downloaded here). Without an appropriate index if our application wants to find, for example, the zip code for a particular city, let’s say Keizer, Oregon (97303), MongoDB would have to scan our entire collection for that city to return the appropriate zip code. In fact, based on our data set, it would have to look through all 29,467 records to be able to find and return the one record.
That’s a lot of unnecessary looking through the database to try to find the correct match of our search term. Imagine if our data set was much larger and included a million or more records. That would be a lot of overhead and searching. If we look at what is going on in a basic query for looking for our city of “KEIZER” buy having MongoDB explain the execution stats for our query, db.zips.find({"city": "KEIZER"}).explain("executionStats"), we can see a few things that are performance bottlenecks.
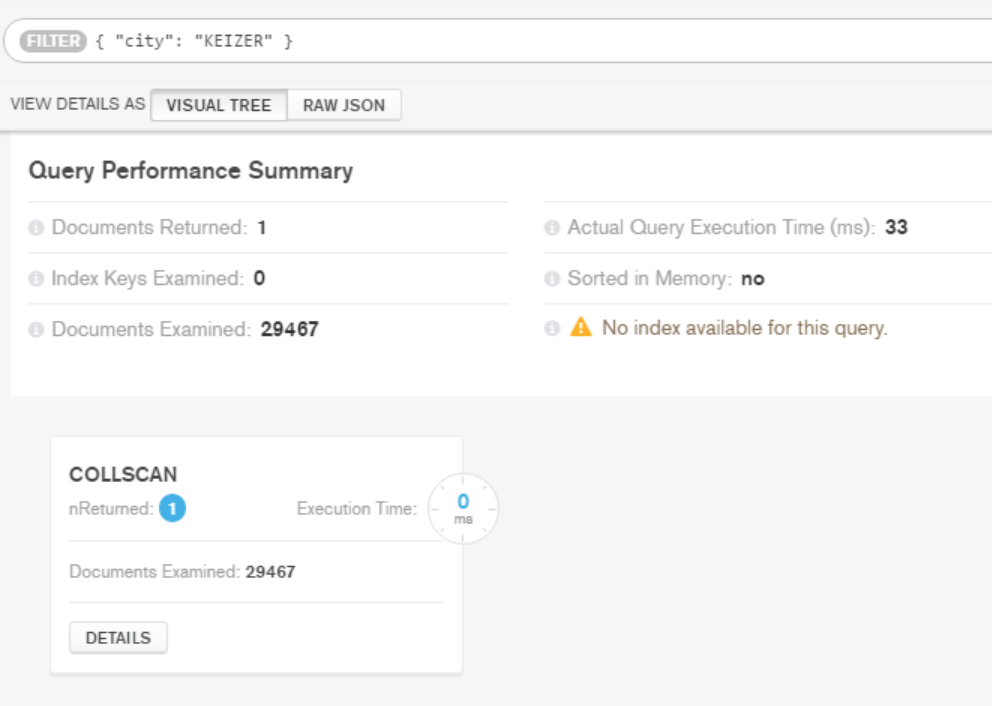
First, we see that even in our relatively small database the query execution time was 34ms. Then, as expected, we looked at all 29,467 documents and that a collection scan was performed to do this query. Again imagine scanning a much larger data set and how that could be a slow process.
Now, what happens if we add an index? Since we are, in this case, searching by city name, it would make sense to create an index on that field. That can be accomplished in the Mongo Shell with the command:
db.zips.createIndex({"city": 1})
Which will create an ascending index on the city field in our collection. Now if we run the same query as before we should expect a couple of things. First, our query execution time should be significantly lower as well as the documents examined number.
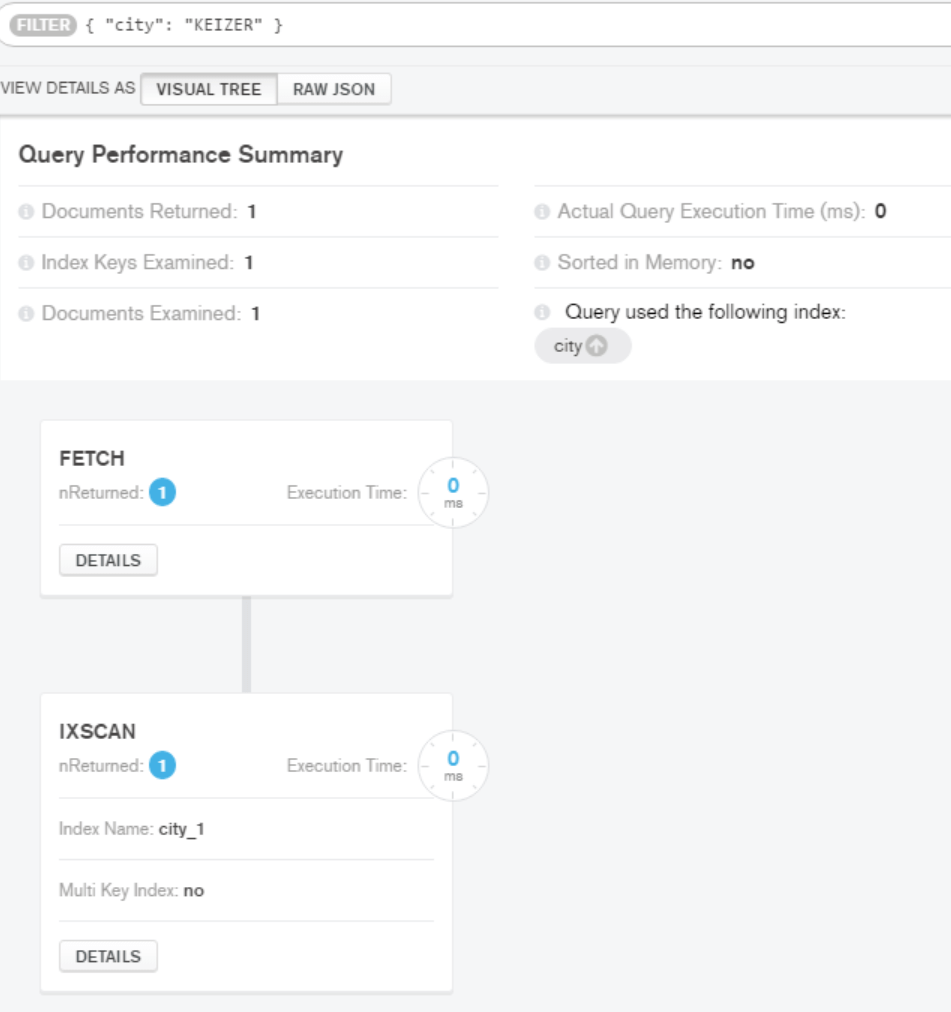
Wow, with an index in place on the city field, doing a search on a city we get some amazing improvements. Our Actual Query Execution Time went from 34ms to zero, we are doing an index scan now (IXSCAN) instead of a collection scan (COLLSCAN) and the number of documents examined decreased to only having to examine a single document. That’s pretty powerful and highlights the need to have indexes on your collection.
After explaining this to MongoDB users I often get a “Why don’t I just index every field then?” response. Well, there’s no such thing as a free lunch, right? Indexes come with overhead. Some examples include memory usage and write performance of your data due to having to update indexes based on new data being stored.
We could also create indexes on multiple fields as well. We might, for example, not only be querying our database on a single city but on a city and state combination. In that case, we might want to look at generating a compound index that references multiple fields in the same index. In this example something like db.zips.createIndex({"city": 1, "state": 1}) might be useful.
Wrap Up
When deciding on an index to create there are a few common things to think about in general. First, create indexes which support your queries. If you are not going to query the zip code collection based on population (“pop”), there isn’t a need to generate an index for that field. Second, if your queries are doing sort operations, make sure that your indexes are supporting those in an efficient way. Third, make sure that your queries are allowing MongoDB to be selective in the results it provides from the query. This allows MongoDB to use the index for the majority of the work.
Indexes are an important part of proper application design with MongoDB. Having a properly designed index can have a large positive impact on the performance of your application. I would highly recommend reading more about them prior to your application deployment to ensure a great end user experience.
