

We’ve solved the Reliability problem with The Judge. We have a system that can scientifically prove whether our Forensic Team is accurate. But there’s a new problem that keeps Directors and CFOs up at night: Sustainability.
In an enterprise environment, using a massive, high-reasoning model (like Claude 3.5 or GPT-4o) for every single bibliography lookup is a “Cognitive Budget” disaster. It’s like hiring a Senior Architect to fix a broken link.
Today, we introduce The Accountant: A Semantic Router that classifies task complexity and routes requests to the cheapest model capable of passing the Judge’s rubric.
1. The Concept of “Tiered Intelligence”
Not all forensic tasks require the same level of “gray matter.” To scale effectively, we must categorize our workload:
- LEVEL 1 (Operational): “Find the standard page count for the 1925 edition of Gatsby.” This is a lookup and retrieval task. Local SLMs (Small Language Models) like Phi-4 or Llama 3.2 excel here.
- LEVEL 2 (Forensic): “Compare the binding grain and typography inconsistencies between two suspected forgeries.” This requires high-dimensional analysis and deep reasoning. This is a job for the Cloud.
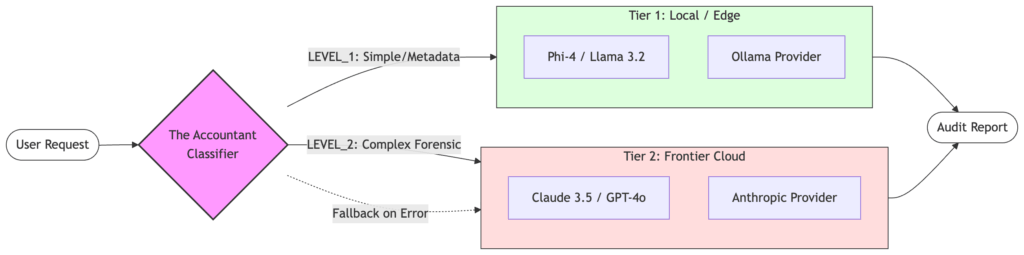
2. Implementing the Router (The Gatekeeper Pattern)
We’ve added router.py to our repository. The logic acts as a gatekeeper.
1. Classification: A lightweight model (the Accountant) reviews the user’s query against our config/prompts.yaml.
2. Economic Decision: If the query is “Level 1”, we trigger the ollama provider. If it’s “Level 2,” we escalate to the anthropic provider.
# The Accountant's Decision Engine in router.py
level = await classify_query(query)
provider = get_provider_for_level(level)
if level == "LEVEL_1":
print("Accountant Decision: LEVEL_1 - Routing to Local SLM to save budget")
else:
print("Accountant Decision: LEVEL_2 - Routing to High-Reasoning Cloud Model")
By defaulting to LEVEL_2 if classification fails, we ensure that we never sacrifice accuracy for cost – we only save money when we are certain the tasks are simple.
3. Projecting the ROI with The Judge
While we built the Accountant (the router), we haven’t yet run a full-scale economic audit in this repository. However, the architecture is designed to scientifically measure this trade-off using the Judge Agent (from our last post).
In an enterprise environment, a Director would use this framework to benchmark a representative sample of historical queries. A typical analysis for tiered intelligence systems shows that the vast majority of “forensic” requests are actually simple metadata lookups. By routing those to a local SLM (Phi-4 or Llama 3.2), we can achieve comparable reliability scores to a frontier cloud model while zeroing out the marginal cost of those specific tokens.
The Theoretical Savings (100k Calls/Month):
- Current Cost (Frontier Cloud for 100% of tasks): ~$7,600/month
- Projected Cost (90/10 Routed Split): ~$1,800/month
- Total Savings: ~76% reduction in inference costs.
| Task Category | Estimated Volume | “Status Quo” Cost (Frontier Cloud) | “Routed” Cost (Accountant/SLM) |
|---|---|---|---|
| Level 1 (Standard Lookup/Formatting) | 90% (90k calls) | ~$4,500 | ~$0 (Local/Self-Hosted) |
| Level 2 (Deep Forensic Analysis) | 10% (10k calls) | ~$3,100 | ~$1,800* |
| Total Cognitive Budget | 100% | ~$7,600 | ~$1,800 |
* Note: Level 2 “Routed” costs are lower here because the Accountant ensures only the most complex 10% of tokens hit the high-cost provider, whereas the “Status Quo” assumes a higher average cost across all 100k calls due to the lack of optimization.
Cognitive Budgeting Insights
As a Director, the responsibility is to build Sustainable Intelligence. If 80% of an AI workload can be moved to local infrastructure or cheaper “Flash” models without dropping our reliability score, I’m not just a developer—I’m a profit center. Semantic routing allows us to scale AI horizontally without the cloud bill scaling vertically.
🛠️ Step into the Clean-Room
The Accountant logic is now live in the repository. You can test the routing logic yourself by running the local orchestrator with the --use-accountant flag.
Explore the Code: MCP Forensic Analyzer on GitHub
(If this architecture helps your team justify their AI spend, consider dropping a ⭐ on the repo!)
The Production-Grade AI Series
- Post 1: The Judge Agent: Who Audits the Auditors? (Reliability)
- Post 2: The Accountant: Optimizing AI Costs with Semantic Routing (Sustainability) – You’re Here
- Post 3: The Guardian: Human-in-the-Loop Governance (Safety) – Coming Soon
Looking for the foundation? Check out my previous series: The Zero-Glue AI Mesh with MCP.
That’s a really insightful point about sustainability – it’s easy to get caught up in the ‘more is better’ approach with AI, but it’s smart to think about the long-term costs.
Exactly. We often talk about ‘AI Performance’ in terms of tokens-per-second, but for a system to be truly sustainable, we have to measure ‘Insight-per-Dollar.’ If we can get 95% of the result for 5% of the cost by using a smaller local model or smarter routing, that’s an engineering win in my book. Thanks for reading!