

(Identity, Input, and the Digital Twin of the Dirt)
We’ve spent the last month teaching an AI agent (the Digital Scribe) to read handwritten 1880 census cursive and build a social graph. It was a rigorous exercise in high-integrity, atomic knowledge mapping.
You might wonder what 19th-century ledgers have to do with a modern harvest. The answer is Identity. The same principles we used to track a person through history—giving them a unique, permanent ID and linking them to their family and home—apply directly to tracking a vineyard block over time. We aren’t just logging data; we are building a “life story” for your land.
But it’s mid-summer in Oregon, and the ledgers are dusty. The Pinot Noir and Maréchal Foch are heavy on the vine. It’s time to move from forensic history to the real-time resilience of The Agile Harvest.
The Mid-Summer Anxiety (The 70% Problem)
It’s 6:00 AM. You’re walking Row 12, checking the clusters. The forecast says 95°F by noon. The vineyard looks beautiful, but last night, you were looking at your contracts. You have 100 acres of prime fruit, and only 30% of it is spoken for.
The “70% Anxiety” is real. In a traditional model, that 70% unsold acreage is just risk—money you’ve spent on labor and trellis maintenance that might never come back. In a Sovereign Vineyard, that’s not risk; it’s a linked set of opportunities.
What do I mean by “Sovereign”? It means you own the “Brain.” Your sugar levels, your yields, and your profit margins stay on a local server you control—not in a third-party cloud app that sells your aggregate data back to big-box competitors.

The Clipboard-to-Sensor Agnosticism
A core pillar of The Agile Harvest is that the AI doesn’t care how the numbers get in, as long as they are accurate. This isn’t about expensive sensor arrays; it’s about Input Agnosticism.
- The High-Tech Path: You have LoRaWAN soil moisture probes and automated brix samplers reporting every hour.
- The “Flannel & Clipboard” Path: You are walking the rows, crushing a grape onto a prism, and typing “13.5 Brix” into a simple chat window on your phone.
To the Digital Scribe, a number is just a number. Whether it comes from a $5,000 automated probe or a handwritten note, once it enters the Knowledge Graph, it becomes a Decision Point.
The Field Agent in Action: The Reasoning Loop
This is where the “Field Agent” metaphor cashes out. Your agent isn’t just a database; it’s a strategic advisor watching the “trajectory” of your fruit.
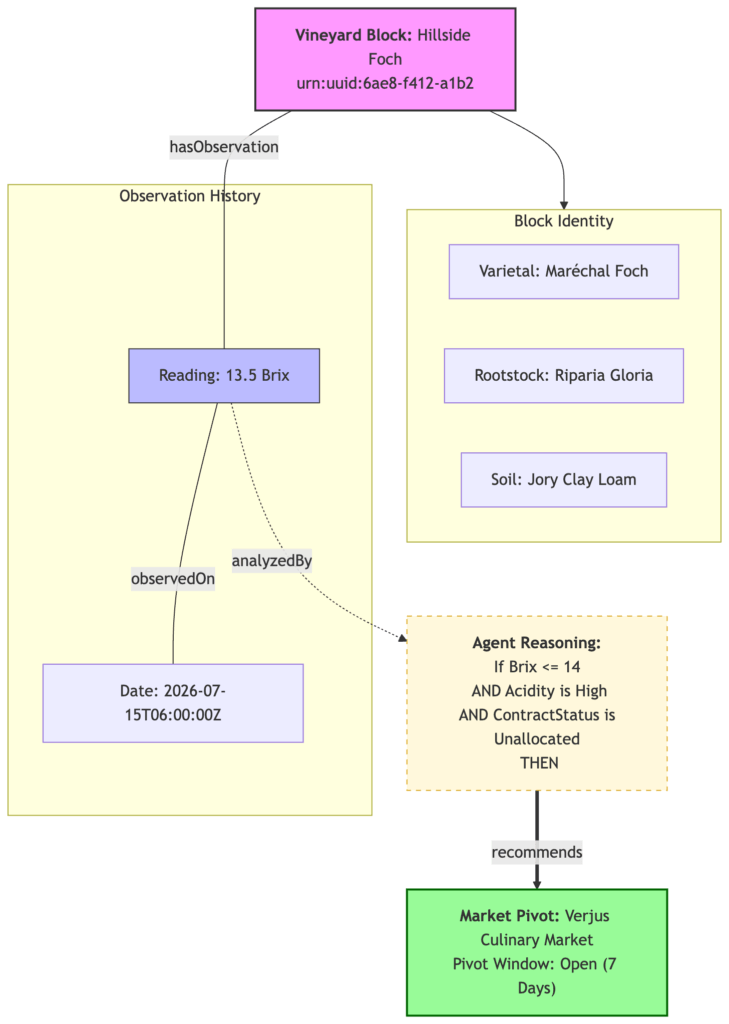
The Sunday Morning Exchange:
Farmer: “Scribe, I just logged a 13.5 Brix and pH of 3.0 on the Foch block. It’s early, but the heat is coming.”
Field Agent: “Copy that. That’s a 2-point sugar jump since Tuesday. Acidity is still very high. I’m cross-referencing our contract list: we still have 15 tons unallocated on this block. My weather tool predicts three days of 95°F+.”
Farmer: “What are my options if we don’t hold for the wine contract?”
Field Agent: “The ‘Verjus Window’ is open. Verjus (unripened green juice) requires high acid and low sugar—exactly what we have today. We are scheduled for green harvesting (thinning fruit) on Tuesday anyway. Instead of dropping that fruit to the mulch, we can divert it to the culinary market. Based on current spot prices, that 70% risk just became a 20% early-season revenue win.”
The Road Ahead
Identifying the “Verjus Window” is just the first step in The Agile Harvest. By treating your vineyard block as a “Digital Twin” with its own identity and history, we’ve built the foundation to pivot before the birds get your crop. Next, we’ll look at the “Pivot Engine” itself—how we connect our local graph to global market APIs to find the highest value for every cluster.
Digital Scribe Series (A Sovereign Path)
Are you facing similar mid-season jitters with unsold inventory or shifting markets? How are you handling the gap between what you grow and what you’ve sold? Reach out on LinkedIn and let’s start a conversation about how local-first AI can help you find your next “Agile Harvest” opportunity.
