

Over the past several weeks, I’ve been spending a lot of time thinking about systems.
Some of that thinking has taken the form of writing.
If you’ve come across any of my recent posts, they might seem like they cover very different topics:
- cataloging rocks in a backyard
- building AI systems using MCP
- working with documents, images, and real-world data
At first glance, they don’t appear to have much in common.
But they’re all exploring the same underlying idea.
The Common Thread
Across all of these posts, the focus has been on a specific kind of problem:
How do we turn messy, real-world inputs into structured, usable systems?
That problem shows up in many different forms.
Sometimes the input is physical:
- objects
- artifacts
- environments
Sometimes it’s digital:
- documents
- images
- logs
Sometimes it’s dynamic:
- motion
- behavior
- sensor data
But the challenge is the same.
The input is unstructured.
The system needs structure.
The Backyard Quarry
One way I explored this idea was through a small project I called the Backyard Quarry.
It started with a simple observation:
There are a lot of rocks in the yard.
From there, the problem evolved into something more interesting:
- how to represent physical objects as data
- how to capture images and measurements
- how to build pipelines around that data
- how to search and organize it
- how to think about digital twins
What began as a small experiment became a way to explore system design in a constrained, tangible setting.
MCP and AI Systems
In parallel, I’ve been writing about building AI systems using MCP.
On the surface, this looks very different.
Instead of rocks, the inputs are:
- documents
- APIs
- models
- agent workflows
But the structure is familiar.
- inputs are ingested
- processed
- transformed
- routed
- used by applications
The system still needs to handle:
- variability
- scale
- imperfect data
- orchestration
Different inputs.
Same patterns.
From Objects to Systems
One of the more useful realizations in working through these ideas is this:
The problem is rarely about the individual object.
It’s about the system that handles many objects over time.
Whether the object is:
- a rock
- a document
- a sensor reading
The questions become:
- how is it represented?
- how does it enter the system?
- how is it transformed?
- how is it stored?
- how is it retrieved?
These are system-level questions.
A Shared Architecture
Across these different domains, a common architecture begins to emerge.
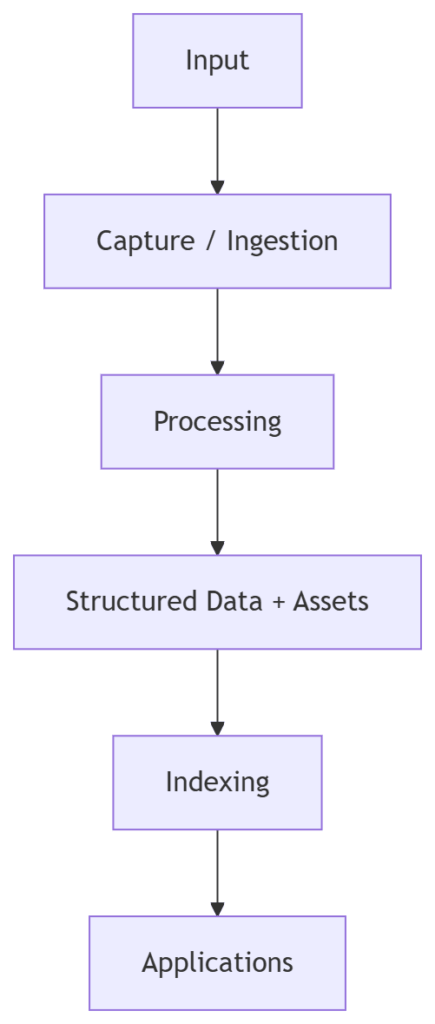
The labels change depending on the domain.
But the structure remains consistent.
Why This Matters
Understanding this pattern makes it easier to approach new problems.
Instead of starting from scratch each time, you can ask:
- Where does the data come from?
- How does it enter the system?
- What transformations are required?
- How will it be used?
This reduces complexity.
It also makes systems more predictable.
What I’m Interested In
Going forward, I’m particularly interested in systems that sit at the boundary between:
- the physical world and digital systems
- unstructured inputs and structured data
- human workflows and automated processes
That includes areas like:
- digital archiving
- photogrammetry and 3D capture
- AI-assisted analysis
- systems that track objects or behavior over time
These problems are messy.
Which is part of what makes them interesting.
A Continuing Exploration
The posts I’ve been writing are not meant to be definitive.
They’re part of an ongoing exploration.
A way to think through problems in public.
And occasionally, a way to use a slightly unusual example — like a pile of rocks — to make broader ideas easier to see.
If You’re Interested
If any of this resonates, you might find these useful:
The Backyard Quarry Series
A systems-focused look at modeling and working with physical objects starting with Turning Rocks Into Data.
MCP and AI Systems
A technical exploration of building agent-based systems and data pipelines. I’d suggest starting with The End of Glue Code: Why MCP is the USB-C Moment for AI Systems.
More to come.
And if nothing else, it turns out that even a backyard can be a good place to think about system design.
