
We’ve built a powerful Forensic Team. They can find books, analyze metadata, and spot discrepancies using MCP.
But in the enterprise, ‘it seems to work’ isn’t a metric. If an agent misidentifies a $50,000 first edition, the liability is real.
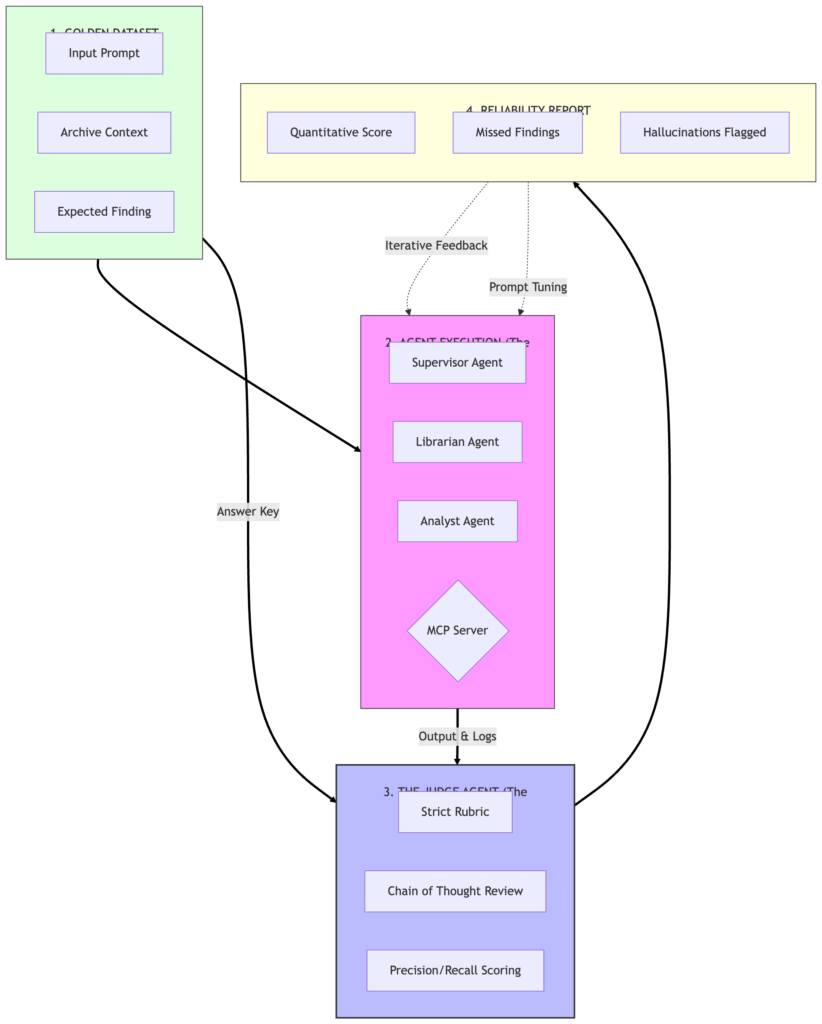
Today, we move from Subjective Trust to Quantitative Reliability. We are building The Judge—a high-reasoning evaluator that audits our Forensic Team against a ‘Golden Dataset’ of ground-truth facts.
Before you Begin
Prerequisites: You should have an existing agentic workflow (see my MCP Forensic Series) and a high-reasoning model (Claude 3.5 Opus/GPT-4o) to act as the Judge.
1. The “Golden Dataset”
Before we can grade the agents, we need an Answer Key. We’re creating tests/golden_dataset.json. This file contains the “Ground Truth”—scenarios where we know there are errors.
Example Entry:
{
"test_id": "TC-001",
"input": "The Great Gatsby, 1925",
"expected_finding": "Page count mismatch: Observed 218, Standard 210",
"severity": "high"
}
Director’s Note: In an enterprise setting, “Reliability” is the precursor to “Permission”. You will not get the budget to scale agents until you can prove they won’t hallucinate $50k errors. This framework provides the data you need for that internal sell.
2. The Judge’s Rubric
A good Judge needs a rubric. We aren’t just looking for “Yes/No.” We want to grade on:
- Precision: Did it find only the real errors?
- Recall: Did it find all the real errors?
- Reasoning: Did it explain why it flagged the record?
3. Refactoring for Resilience
Before building the Judge, we had to address a common “Senior-level” trap: hardcoding agent logic. Based on architectural reviews, we moved our system prompts from the Python client into a dedicated config/prompts.yaml.
This isn’t just about clean code; it’s about Observability. By decoupling the “Instructions” from the “Execution,” we can now A/B test different prompt versions against the Judge to see which one yields the highest accuracy for specific models.
4. The Implementation: The Evaluation Loop
We’ve added evaluator.py to the repo. It doesn’t just run the agents; it monitors their “vital signs.”
- Error Transparency: We replaced “swallowed” exceptions with structured logging. If a provider fails, the system logs the incident for diagnosis instead of failing silently.
- The Handshake: The loop runs the Forensic Team, collects their logs, and submits the whole package to a high-reasoning Judge Agent.
The Evaluator-Optimizer Blueprint
This diagram represents our move from “Does the code run?” to Does the intelligence meet the quality bar?” This closed-loop system is required before we can start the fiscal optimization of choosing smaller models to handle simpler tasks.
Director-Level Insight: The “Accuracy vs. Cost” Curve
As a Director, I don’t just care about “cost per token.” I care about Defensibility. If a forensic audit is challenged, I need to show a historical accuracy rating. By implementing this Evaluator, we move from “Vibe-checking” to a Quantitative Reliability Score. This allows us to set a “Minimum Quality Bar” for deployment. If a model update or a prompt change drops our accuracy by 2%, the Judge blocks the deployment.
The Production-Grade AI Series
- Post 1: The Judge Agent — You are here
- Post 2: The Accountant (Cognitive Budgeting & Model Routing) — Coming Soon
- Post 3: The Guardian (Human-in-the-Loop Handshakes) — Coming Soon
Looking for the foundation? Check out my previous series: The Zero-Glue AI Mesh with MCP.