We have spent the last several weeks dismantling the traditional “Glue Code” approach to AI and replacing it with a standardized, governed, and sovereign architecture. The result is the Sovereign Vault: a forensic expert system built on the Model Context Protocol (MCP).
This post serves as the master index and architectural map for the entire series. Whether you are looking for local vision, PII redaction, or agentic governance, you will find the path below.
The Five Design Principles
The Sovereign Vault isn’t just a project; it’s a reference implementation for five core patterns of modern AI systems:
- Local-First Perception: We process high-resolution artifacts at the edge using local SLMs to ensure data sovereignty.
- Standardized Tool Discovery: By using MCP, our agents dynamically discover forensic tools without custom integration code.
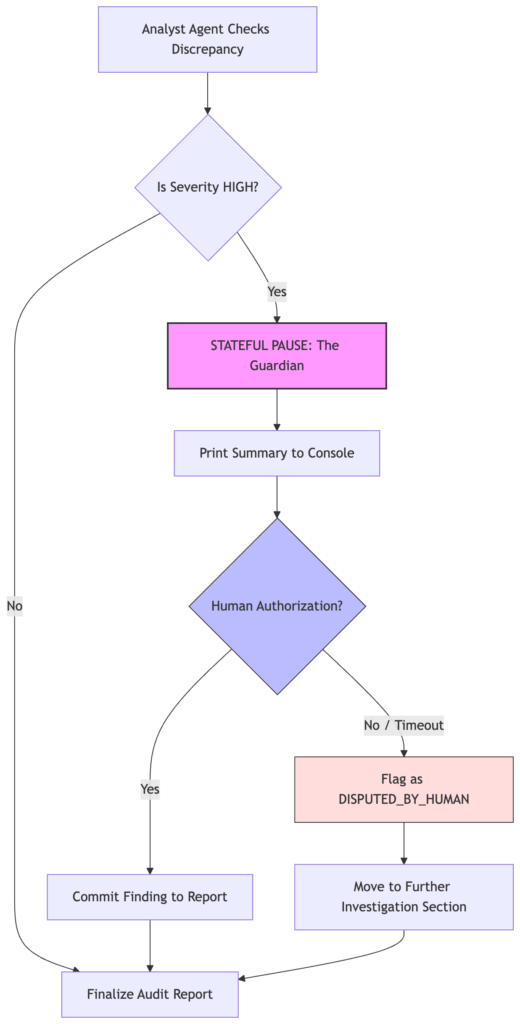
- The Sovereign Airlock: A multi-layered governance gate (The Redactor and The Guardian) that controls exactly what context leaves your network.
- Cognitive Budgeting: We use semantic routing to send simple tasks to local SLMs and complex reasoning to frontier cloud models.
- Evaluatable Intelligence: We move beyond “vibes” by using an LLM-as-a-Judge framework to benchmark forensic accuracy.
The Reader’s Journey: From Librarian to Auditor
The series follows a logical progression of complexity, moving from simple data retrieval to high-reasoning expert verdicts.
Phase 1: The Foundation
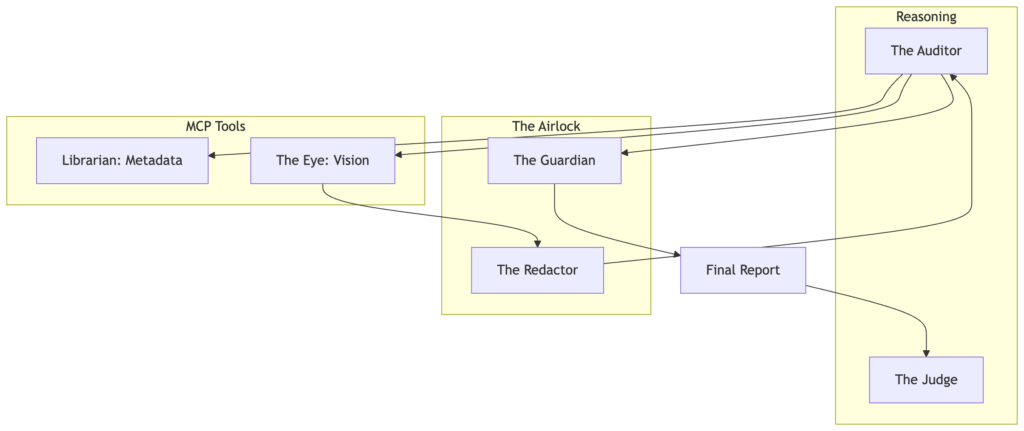
- We established the “Zero-Glue” stack. We build the Librarian, our first MCP server, which exposes archival metadata as standardized tools and resources.
Phase 2: Scale and Sustainability
- We introduced The Accountant (Semantic Routing) to manage costs and The Judge (Evaluation) to ensure reliability through golden datasets. We also implement the first version of The Guardian for basic human-in-the-loop oversight.
Phase 3: Sovereignty and Perception
- We then gave the system Eyes using local Llama 3.2-Vision. To protect our data, we build The Redactor, a privacy airlock that scrubs PII at the edge before cloud egress.
Phase 4: Synthesis and Governance
- We introduced The Auditor, a high-reasoning persona that synthesizes visual and archival data into a final verdict. We harden our governance with a severity-aware Guardian handshake and conclude with the strategic case for MCP as the “USB-C for AI.”
The Final Architecture
Take the First Step
The entire codebase is open-source and designed for you to fork, explore, and break.
The Repository: mcp-forensic-analyzer
Quick Start: Run the 5-minute demo to see the full pipeline in action.
The end of glue code is here. It’s time to start building with protocols, not just prompts.
Miss Part of the Series?
- The Local Eye (Sovereign Vision)
- The Sovereign Redactor – A Precision-Guided Privacy Airlock
- The Auditor – High-Reasoning Synthesis and the Ethics of Governance
- The Sovereign Vault: Building High-Integrity AI with MCP & Local Vision