Architecting for Reliability in the Age of Multi-Agent Systems
We are currently over-indexing on “Model Orchestration.”
Every week, a new library, a new vector database, or a new framework tops the GitHub trending charts.
This week, it might be LangGraph. The next CrewAI. Something else is right behind it.
Every week, the same question shows up:
“Which stack should I use to build a reliable multi-agent system?”
It’s the wrong question.
Because I’ve yet to see a system fail due to the wrong framework, language, or database.
I’ve seen them fail because they couldn’t recover state, couldn’t control context, and couldn’t explain what they just did.
There’s a persistent belief that the logo on the documentation is the secret sauce for a production-ready system.
It isn’t. In fact, if you’re spending the majority of your time debating the stack, you’re missing the architectural patterns that actually determine whether your agents will succeed or hallucinate into oblivion.
The Illusion of the Framework
A Multi-Agent System (MAS) is not a library problem. It is a State Management problem disguised as an AI problem. Whether you use a graph-based logic or a role-based queue, the fundamental challenges and failure modes remain identical:
- lost state
- bloated context
- untraceable decisions
The stack you choose is merely the syntax you use to solve universal engineering constraints.
The Core Thesis: Reliability in agentic workflows is derived from patterns, not packages. A secure, scalable system built in Python looks fundamentally the same as one built in Rust if the underlying system primitives are respected.
The Three Constants of Reliable Agents
Regardless of your tools, your architecture must solve for these three pillars to move from a “cool demo” to a production asset:
- State is Sovereign
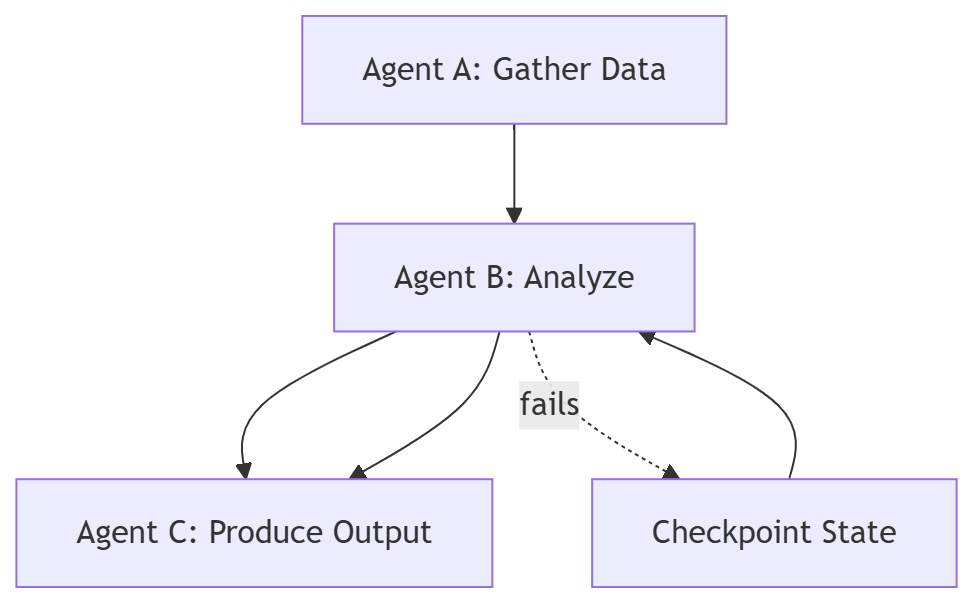
If an agentic loop fails at step 7 of 12, does your system restart from scratch? If so, your stack doesn’t matter because your architecture is broken. A resilient system requires Deterministic Checkpointing:- Capture the full thread state.
- Preserve intent, not just data.
- Resume execution without replaying the entire workflow.
Without this, your system is just a loop with amnesia.
- The Context Tax
Context windows are not infinite. In reality, every token you give an agent is a tax on its reasoning. The “how” isn’t about which LLM you use; it’s about the Routing Layer:
- Classify intent
- Expose only relevant tools
- Minimize context surface area
Less context doesn’t limit the system—it sharpens it.
- Governance as a First-Class Citizen
An agent is a service principal. If it cannot be audited, revoked, or sandboxed at the identity level, it shouldn’t have access to your data or exist in production.
A reliable system enforces:
– Least-Privilege Authorization, ensuring agents operate within a cryptographic “box” regardless of whether they are running in a Docker container or a serverless function.
– Scoped tool usage
– Traceable execution
Example
Consider a simple multi-agent workflow:
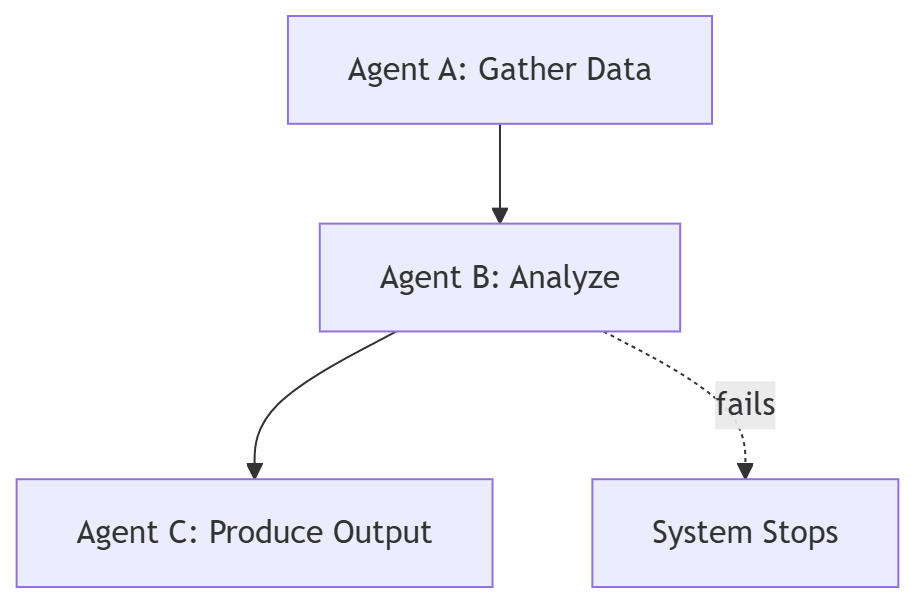
If your system can’t resume from that point with the same context and intent, you don’t have a system.
You have a demo.
A reliable system looks different.
The Framework-Agnostic Checklist
| Pillar | The Real Question |
|---|---|
| Coordination | How do agents hand off work without bloating context or losing intent? |
| Observability | Can we trace every decision back to inputs and reasoning steps? |
| Resilience | What happens when a model fails mid-workflow? Can we resume without replaying? |
| Sovereignty | Who owns the data and execution environment—us or the platform? |
Closing Thoughts
These are not new problems. They’re just showing up in a new layer.
Stop chasing the framework. A system built in Python and one built in Rust will fail in exactly the same ways if the architecture is wrong.
The difference isn’t the stack. It’s whether you’ve designed for:
- State
- Context
- Control
The tools are interchangeable. The architecture is not.
This is the foundation for the upcoming Sovereign Synapse series—where we move from theory to a local-first system that treats memory, context, and ownership as first-class concerns.