

At this point in the Backyard Quarry project, something subtle has happened.
We started with a pile of rocks.
We now have:
- a schema
- a capture process
- stored images
- searchable metadata
- classification
- lifecycle states
Each rock has a record.
Each record represents something in the physical world.
And that leads to a useful observation.
We’re no longer just cataloging rocks.
We’re building digital representations of them.
What Is a Digital Twin?
In simple terms, a digital twin is:
A structured digital representation of a physical object.
That representation can include:
- identity
- properties
- visual data
- state
- history
In the context of the Quarry, a rock’s digital twin might look like:
rock_id: QRY-042
weight_lb: 12.3
dimensions_cm: 18 x 10 x 7
color: gray
rock_type: granite
status: for_sale
images: [rock_042_1.jpg, rock_042_2.jpg]
model: rock_042.obj
It’s not the rock itself.
But it’s a useful abstraction of it.
More Than Just Metadata
At first glance, a digital twin might look like a simple database record.
But there’s an important difference.
A well-designed digital twin combines multiple types of data:
- structured metadata (easy to query)
- unstructured assets (images, models)
- derived attributes (classification, embeddings)
- state over time
It’s not just describing the object.
It’s enabling interaction with it through software.
The Time Dimension
One of the most important aspects of a digital twin is that it can change over time.
Even a rock — which is about as static as objects get — has a lifecycle in the system:
collected → cataloged → listed_for_sale → sold
Each transition adds context.
Now we’re not just storing a snapshot.
We’re tracking a history.
This becomes much more important in other domains.
Where This Shows Up
The interesting part is that this pattern isn’t unique to rocks.
It appears in many different systems.
Manufacturing
- digital twins of machine parts
- tracking condition and usage
- linking physical components to system data
Museums and Archives
- artifacts with metadata, images, provenance
- digitized collections
- searchable historical records
Agriculture
- crops tracked over time
- environmental data
- growth and yield metrics
Healthcare and Motion
- human movement captured as data
- gait analysis
- rehabilitation tracking
This last one starts to look a lot like something else entirely.
From Objects to Systems
What the Backyard Quarry demonstrates, in a small way, is that once you:
- represent objects as data
- capture their properties
- store and index them
you’ve created the foundation for a larger system.
The digital twin becomes a building block.
And systems are built from collections of these building blocks.
The Abstraction Layer
A useful way to think about digital twins is as an abstraction layer.
They sit between:
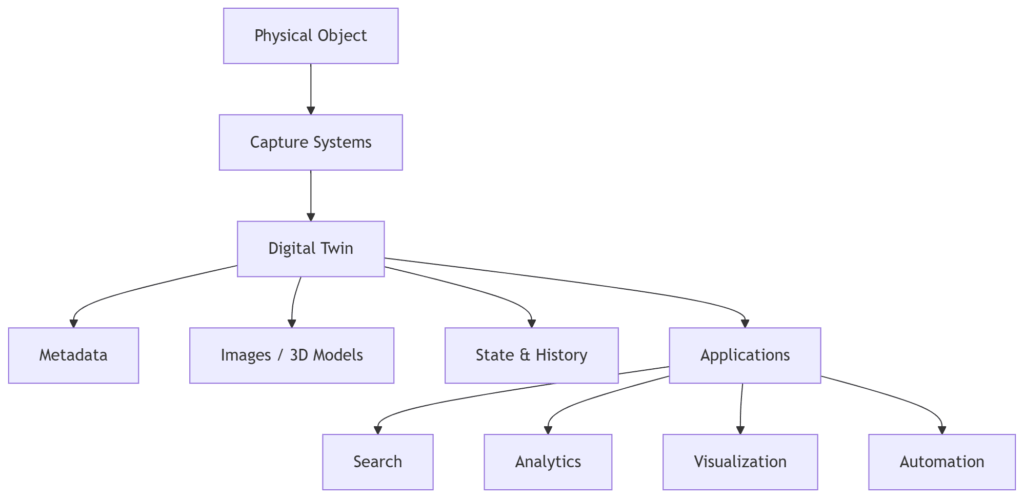
Applications don’t interact with rocks directly.
They interact with the representation of rocks.
That layer enables:
- search
- analytics
- visualization
- automation
Without it, everything remains manual and unstructured.
The Limits of the Model
Of course, digital twins are not perfect representations.
They are approximations.
Some properties are easy to capture.
Others are difficult or impossible.
Even in the Quarry:
- weight is approximate
- dimensions are imprecise
- visual data depends on lighting
- 3D models may be incomplete
The goal isn’t perfect fidelity.
It’s usefulness.
The Real Insight
At this point, the Backyard Quarry starts to feel less like a joke and more like a small version of a much larger idea.
Many modern systems are built around digital twins.
Not because the concept is new.
But because we now have the tools to make it practical:
- cheap sensors
- high-resolution cameras
- scalable storage
- machine learning
The pattern has existed for a long time.
The difference is that we can now implement it at scale.
What Comes Next
So far, the Quarry system works at a small scale.
A handful of rocks.
A manageable dataset.
But what happens when the number of objects grows?
When the dataset becomes:
- hundreds
- thousands
- or millions
The next post explores that question.
Because designing a system for a small dataset is one thing.
Designing a system that scales is something else entirely.
And somewhere along the way, it becomes clear that a pile of rocks is enough to illustrate ideas that show up across entire industries.
Yet another surprise in this Backyard Quarry journey.
The Rock Quarry Series
- Turning Rocks into Data
- Designing a Schema for Physical Objects
- Capturing the Physical World
- Searching a Pile of Rocks
- Digital Twins for Physical Objects – This Post
- Scaling the Quarry
- Systems Beyond the Backyard
- From Rocks to Reality

