Pattern Defined
Precise Definition: Context Compression is an inference pattern that utilizes
a specialized “selector” model or a ranker to distill large volumes of retrieved
data into its most salient semantic components, removing redundant or irrelevant
tokens before the final inference pass.
Problem Being Solved
We are currently fighting the “Lost in the Middle” phenomenon. Even with massive
token windows, LLM performance degrades significantly when relevant information is
buried deep within a context block; more data often leads to less accuracy.
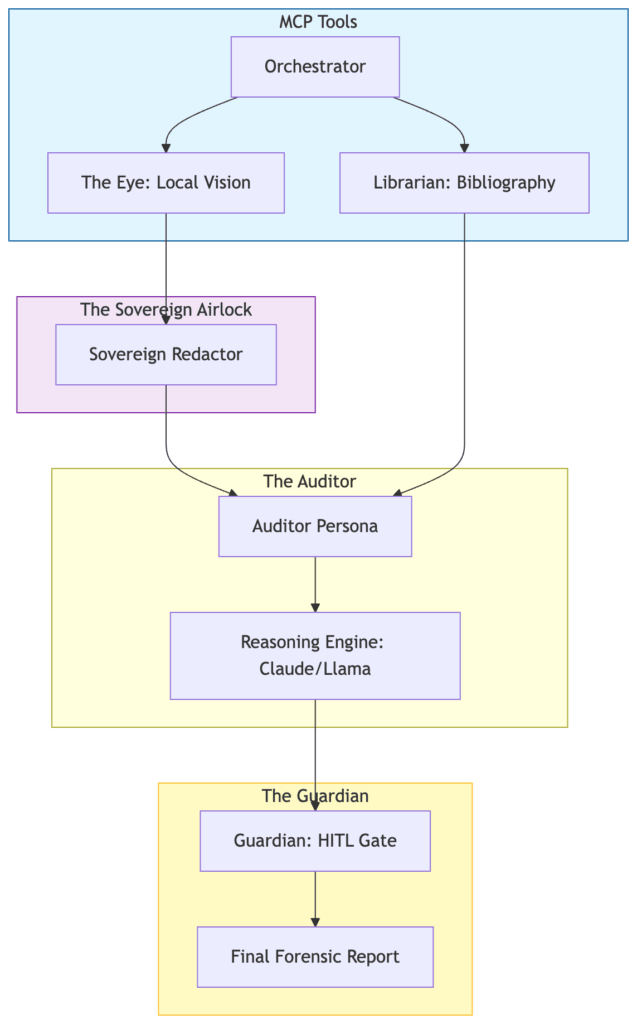
For a Director of Engineering, this is a direct threat to the
Sovereign Vault’s
integrity. Every irrelevant token passed to the model is a potential point of
failure for privacy airlocks and data governance. As established with the
Sovereign Redactor,
minimizing the noise isn’t just about saving money—it is about shrinking the
surface area for hallucinations and privacy leaks.
Use Case
Consider an Archival Intelligence
system processing 1880s shipping ledgers. A single query about “cargo weights in
1884” might pull 20 pages of scanned text. Most of those pages contain sailor
names and weather reports that have no bearing on the weight data.
Without compression, the model has to “read” the entire ledger, leading to high
costs and potential confusion. With the Context Compression pattern, a smaller,
faster ranker identifies the specific sentences regarding “tonnage” and “cargo,”
passing only those 200 relevant words to the high-reasoning model. The Forensic
Auditor gets a precise answer in half the time.
Solution
The pattern typically follows a three-step pipeline:
- Retrieve: Fetch the top documents using standard RAG.
- Compress: Use a technique like LongLLMLingua (a token-pruning method
developed by Microsoft Research) or a Cross-Encoder to rank and prune tokens. - Synthesize: Pass the condensed, high-signal prompt to the final model.
flowchart LR
A([User Query]) --> B[RAG Retrieval\nTop N Documents]
B --> C[Compression Layer\nLongLLMLingua /\nCross-Encoder]
C --> D[High-Signal\nCondensed Prompt]
D --> E([Frontier Model\nSynthesis])
_The tree-step compression pipeline: retrieve broadly, compress precisely, synthesize confidently.
In an MCP or FastAPI-based system, this happens at the “Glue Code” layer, where
you programmatically filter the retrieval results before they hit the LLM’s prompt
window.
Trade-Offs
The trade-off is Latency in the Retrieval Step vs. Reliability in the Synthesis
Step. Adding a compression layer adds a few hundred milliseconds to your
pipeline, but it significantly reduces the final generation time and token cost.
From a leadership perspective, the risk is Over-Pruning. Tuning the “compression
ratio” to ensure the Forensic Auditor doesn’t lose critical edge cases is a new
engineering requirement—one that takes place in those two extra sprint cycles we
discussed in the series opener.
Summary
Context Compression is the difference between handing a researcher a stack of 100
books and handing them a one-page summary of the relevant chapters. It ensures
that your high-reasoning models only see what matters.
Next Up
In two weeks, we go deep on the Hybrid Retrieval Pattern and explore why your data needs a
map, not just a list.
Inference Pattern Series
- Inference Renaissance
- Speculative Decoding
- Context Compression Pattern – This Post
- Hybrid Retrieval – June 19
- Agent Tool-Calling – July 3
- Multi-Model Routing – July 17