At the beginning of this series, the problem seemed simple.
There were a lot of rocks in the yard.
Some were small.
Some were large.
A few were firmly in what I’ve been calling Engine Block Class.
The original idea was straightforward: catalog them, maybe sell a few, and build a small system around the process.
Along the way, the project grew.
What We Built
Across the previous posts, the Backyard Quarry gradually evolved into something more structured.
We explored:
- designing a schema for physical objects
- capturing images and measurements
- building ingestion pipelines
- indexing and searching the dataset
- representing objects as digital twins
- scaling the system as the dataset grows
None of these ideas are particularly new on their own.
But when combined, they form a recognizable structure.
The Pattern Behind the Project
What the Quarry experiment revealed is that many modern systems share the same underlying architecture.
It doesn’t matter whether the input is:
- rocks in a backyard
- industrial machine parts
- museum artifacts
- scanned environments
- sensor data
- documents or images
The pattern remains surprisingly consistent.
We start with the physical world.
We capture information from it.
We transform that information into structured data.
Then we build systems on top of that structure.
The Signature Architecture
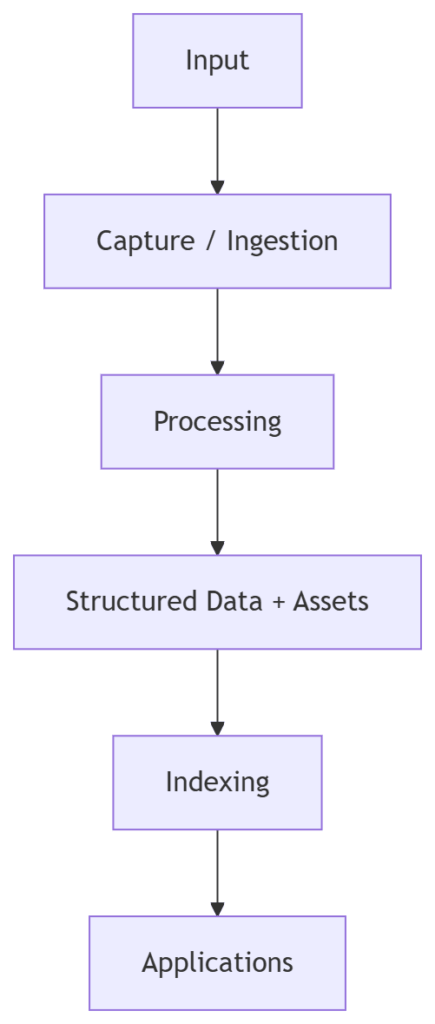
At a high level, the pattern looks like this:
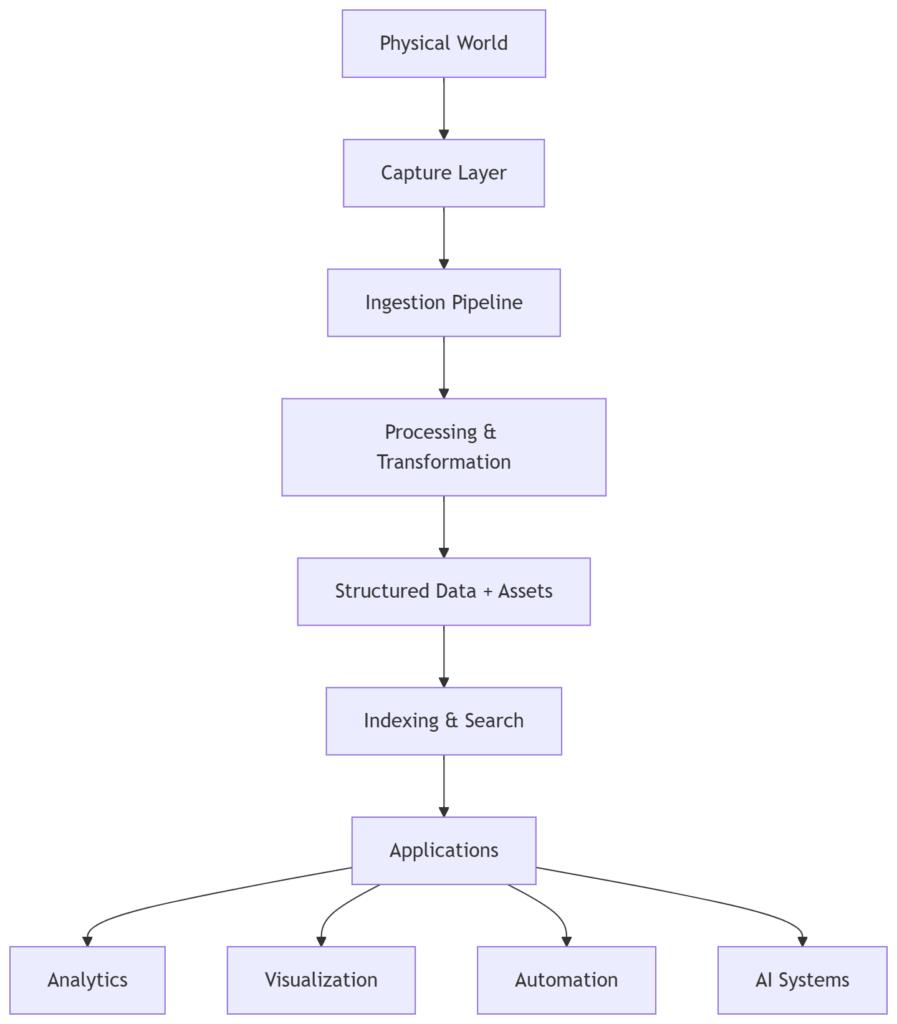
Each layer has a role:
Capture Layer
The interface between the real world and the system.
Examples:
- cameras
- sensors
- manual input
- scanning systems
Ingestion Pipeline
Raw inputs enter the system.
Queues and ingestion services buffer incoming data.
This stage provides resilience and scalability.
Processing & Transformation
Raw inputs are converted into usable forms.
Examples:
- metadata extraction
- photogrammetry
- feature generation
- classification
Structured Data + Assets
The system stores both:
- structured records
- unstructured assets
This is where digital twins live.
Indexing & Search
Data becomes usable.
Indexes, embeddings, and search systems allow retrieval and exploration.
Applications
Finally, systems are built on top of the data:
- dashboards
- analytics
- automation
- AI systems
Recognizing Systems
One of the more interesting outcomes of the Quarry project is how quickly the pattern became recognizable.
Once you see it, it’s hard to miss.
Manufacturing systems follow this structure.
Archival systems follow this structure.
Many modern AI systems follow this structure.
Even systems designed to analyze motion or sensor data follow this structure.
Different inputs.
Same architecture.
Systems Thinking
The biggest shift in perspective comes when you stop thinking about individual objects and start thinking about the system as a whole.
Instead of asking:
- How do we catalog this rock?
You start asking:
- How does the system handle many objects over time?
This change in perspective leads to different kinds of decisions:
- how pipelines are structured
- how data flows through the system
- how failures are handled
- how the system evolves
At that point, the problem is no longer about objects.
It’s about systems.
A Small Experiment
The Backyard Quarry began as a small experiment.
A dataset that happened to be available.
A problem that seemed simple.
But small experiments are often useful.
They allow ideas to emerge in a manageable setting.
The same architectural questions that appear in large organizations also appear here — just at a smaller scale.
The Real Takeaway
The real lesson from the Quarry isn’t about rocks.
It’s about recognizing patterns.
Modern systems often share common structures.
Once you understand those structures, it becomes easier to design new systems.
You start to see the same ideas appearing in different places.
And that recognition becomes a powerful tool.
One Last Observation
Some engineering lessons come from large projects.
Others come from experiments.
Occasionally, they come from a pile of rocks in the backyard.
And if you happen to need a carefully documented specimen from the Backyard Quarry, inventory may still be available.
Shipping, however, remains an unsolved optimization problem.
The Rock Quarry Series
- Turning Rocks into Data
- Designing a Schema for Physical Objects
- Capturing the Physical World
- Searching a Pile of Rocks
- Digital Twins for Physical Objects
- Scaling the Quarry
- Systems Beyond the Backyard
- From Rocks to Reality – This Post